概述
在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。这些变量会被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是,Spark还是为两种常见的使用模式提供了两种有限的共享变量:广播变(broadcast variable)和累加器(accumulator)
为什么需要广播变量
如果我们要在分布式计算里面分发大对象,例如:字典,集合,黑白名单等,这个都会由Driver端进行分发,一般来讲,如果这个变量不是广播变量,那么每个task就会分发一份,这在task数目十分多的情况下Driver的带宽会成为系统的瓶颈,而且会大量消耗task服务器上的资源,如果将这个变量声明为广播变量,那么知识每个executor拥有一份,这个executor启动的task会共享这个变量,节省了通信的成本和服务器的资源。
图解广播变量
不使用广播变量
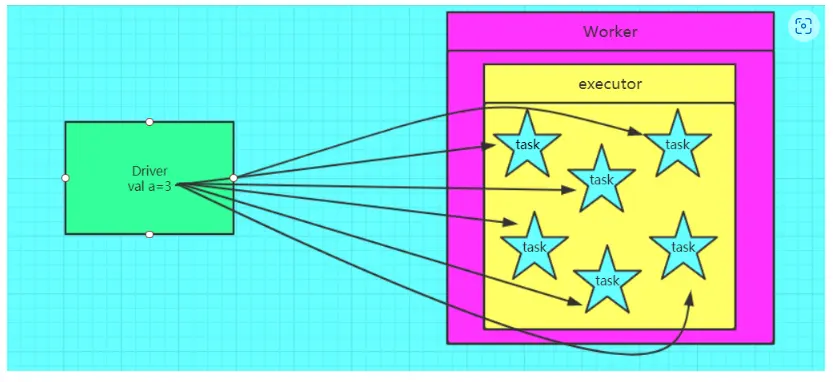 使用广播变量
使用广播变量
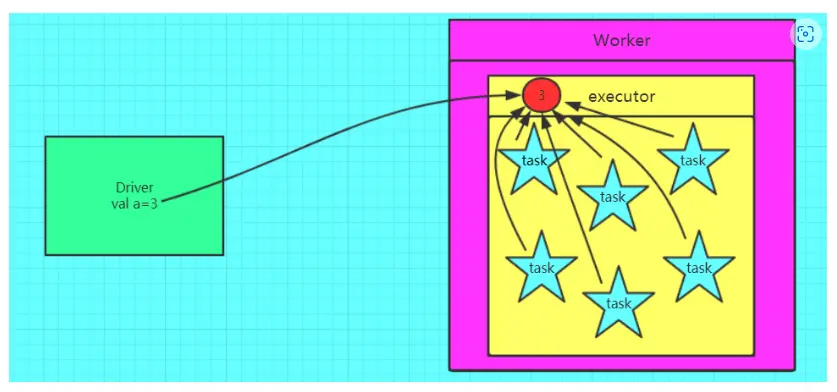 可知: 如果使用广播变量,一个executor 只有一个driver 变量的副本,节省资源,而不是用的话,同一个executor 的不同task 都会有这个变量的副本,网络IO就会成为瓶颈。
可知: 如果使用广播变量,一个executor 只有一个driver 变量的副本,节省资源,而不是用的话,同一个executor 的不同task 都会有这个变量的副本,网络IO就会成为瓶颈。
如何定义广播变量
| |
注意点
变量一旦被定义为一个广播变量,那么这个变量只能读,不能修改
1、能不能将一个RDD使用广播变量广播出去?
- 不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
2、 广播变量只能在Driver端定义,不能在Executor端定义。
3、 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
4、如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本。
5、如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本。
为什么需要累加器
在spark应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会再driver端进行全局汇总,即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
图解累加器
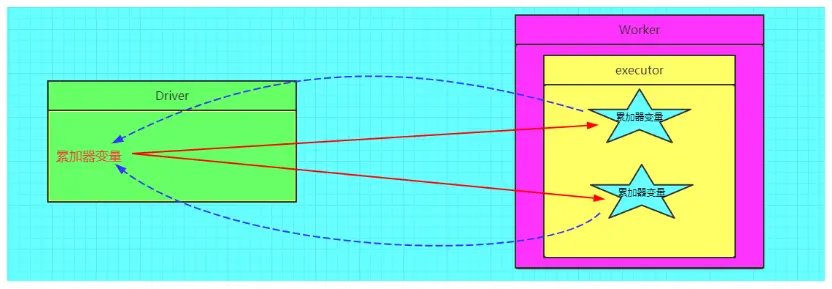
不使用累加器

使用累加器
如何定义一个累加器?
| |
注意点
1、 累加器在Driver端定义赋初始值,累加器只能在Driver端读取最后的值,在Excutor端更新。
2、累加器不是一个调优的操作,因为如果不这样做,结果是错的
哪些变量在Drive 端,哪些在Executor 端
driver & executor
driver是运行用户编写Application 的main()函数的地方,具体负责DAG的构建、任务的划分、task的生成与调度等。job,stage,task生成都离不开rdd自身,rdd的相关的操作不能缺少driver端的sparksession/sparkcontext。
executor是真正执行task地方,而task执行离不开具体的数据,这些task运行的结果可以是shuffle中间结果,也可以持久化到外部存储系统。一般都是将结果、状态等汇集到driver。但是,目前executor之间不能互相通信,只能借助第三方来实现数据的共享或者通信。
那么,编写的Spark程序代码,运行在driver端还是executor端呢?
通常我们在本地测试程序的时候,要打印RDD中的数据。
在本地模式下,直接使用rdd.foreach(println)或rdd.map(println)在单台机器上,能够按照预期打印并输出所有RDD的元素。
但是,在集群模式下,由executor执行输出写入的是executor的stdout,而不是driver上的stdout,所以driver的stdout不会显示这些!
要想在driver端打印所有元素,可以使用collect()方法先将RDD数据带到driver节点,然后在调用foreach(println)(但需要注意一点,由于会把RDD中所有元素都加载到driver端,可能引起driver端内存不足导致OOM。如果你只是想获取RDD中的部分元素,可以考虑使用take或者top方法)
总之,在这里RDD中的元素即为具体的数据,对这些数据的操作都是由负责task执行的executor处理的,所以想在driver端输出这些数据就必须先将数据加载到driver端进行处理。
最后做个总结:所有对RDD具体数据的操作都是在executor上执行的,所有对rdd自身的操作都是在driver上执行的。比如foreach、foreachPartition都是针对rdd内部数据进行处理的,所以我们传递给这些算子的函数都是执行于executor端的。但是像foreachRDD、transform则是对RDD本身进行一列操作,所以它的参数函数是执行在driver端的,那么它内部是可以使用外部变量,比如在Spark Streaming程序中操作offset、动态更新广播变量等。