简介
总体上来说,Spark的流程和MapReduce的思想很类似,只是实现的细节方面会有很多差异。 首先澄清2个容易被混淆的概念:
- Spark是基于内存计算的框架
- Spark比Hadoop快100倍
第一个问题是个伪命题。
任何程序都需要通过内存来执行,不论是单机程序还是分布式程序。
Spark会被称为 基于内存计算的框架 ,主要原因在于其和之前的分布式计算框架很大不同的一点是,Shuffle的数据集不需要通过读写磁盘来进行交换,而是直接通过内存交换数据得到。效率比读写磁盘的MapReduce高上好多倍,所以很多人称之为 基于内存的计算框架,其实更应该称为 基于内存进行数据交换的计算框架。
至于第二个问题,有同学说,Spark官网 就是这么介绍的呀,Spark run workloads 100x faster than Hadoop。
这点没什么问题,但是请注意官网用来比较的 workload 是 Logistic regresstion。 注意到了吗,这是一个需要反复迭代计算的机器学习算法,Spark是非常擅长在这种需要反复迭代计算的场景中(见问题1),而Hadoop MapReduce每次迭代都需要读写一次HDFS。以己之长,击人之短 差距可向而知。
如果都只是跑一个简单的过滤场景的 workload,那么性能差距不会有这么多,总体上是一个级别的耗时。
所以千万不要在任何场景中都说 Spark是基于内存的计算、Spark比Hadoop快100倍,这都是不严谨的说法。
逻辑执行图
1. 弹性分布式数据集
RDD是Spark中的核心概念,直译过来叫做 弹性分布式数据集。
所有的RDD要么是从外部数据源创建的,要么是从其他RDD转换过来的。RDD有两种产生方式:
- 从外部数据源中创建
- 从一个RDD中转换而来 你可以把它当做一个List,但是这个List里面的元素是分布在不同机器上的,对List的所有操作都将被分发到不同的机器上执行。 RDD就是我们需要操作的数据集,并解决了 数据在哪儿 这个问题。
有了数据之后,我们需要定义在数据集上的操作(即业务逻辑)。 回想一下我们之前经历的流程:
- 一开始我们什么都没有,只有分散在各个服务器上的日志数据,并且通过一个简单的脚本遍历连接服务器,执行相关的统计逻辑
- 我们接触了MapReduce计算框架,并定义了Map和Reduce的函数接口来实现计算逻辑,从而用户不比关心计算逻辑拆分与分发等底层问题
虽然MapReduce已经解决了我们分布式计算的需求,但是其编程范式只有map和reduce两个接口,使用不灵活。
在Spark中,RDD提供了比MapReduce编程模型丰富得多的编程接口,如:filter、map、groupBy等都可以直接调用实现(这些操作本质上也划分为Map和Reduce两种类型)。
现在,统计PV的例子中实现计算逻辑的伪代码可以这么写:
| |
在RDD进行操作行为可以划分为两种:
- Transformation:如filter、map、groupBy等,将会产生另外一个RDD
- Action:如count、saveAsTextFile等,触发整个逻辑图的计算流程 一个Spark程序可以看做是 一个或者多个RDD的完整生命周期,从诞生到发展,到变换,再到输出之后销毁。
2. 依赖关系
现在你可能会问,使用MapReduce,通过指定数据源定义了操作数据集,通过Map和Reduce两个函数接口划分了 能够分发到各个节点上并行执行的 和 需要经过一定量的结果合并之后才能够继续执行的 两种任务,并基于这两种接口类型的任务去拆分和分发计算逻辑。
那么Spark中是如何做的呢?
Spark中通过RDD定义了 分布式数据集,通过RDD的编程接口定义了计算逻辑,但是Spark是如何根据RDD中定义的逻辑来划分 能够分发到各个节点上并行执行的 和 需要经过一定量的结果合并之后才能够继续执行的 任务,从而实现计算逻辑的拆分和分发呢?
其实和MapReduce一样,Spark中虽然提供了丰富的算子给用户实现计算逻辑,但是这些算子最终仍然会被归为两类:Map和Reduce。
前面我们说过,在RDD上执行Transformation操作会产生另外一个RDD,随即,RDD之间将会产生依赖关系和父子RDD关系。
而RDD中的依赖关系分为两种:
1、完全依赖:又称为窄依赖,父RDD中一个分区的数据只被子RDD中对应的一个分区使用(1对1) 2、部分依赖:又称为宽依赖,父RDD中一个分区的数据会被子RDD中对应的多个分区使用(1对多 or 多对多)
看到了吗,最后RDD通过依赖关系又回到了我们之前讨论的话题:能够分发到各个节点上并行执行的 和 需要经过一定量的结果合并之后才能够继续执行的 两种任务。
对于完全依赖来说,各个分区之间的任务是互不影响的,所以其能够发到各个节点上并行执行。
对于部分依赖来说,子RDD的某个分区可能依赖于父RDD的多个分区,所以其需要经过一定量的结果合并(依赖的所有父RDD分区)之后才能够继续执行。
定义了这两种类型的任务之后,Spark就可以根据依赖关系进行 计算逻辑的拆分与分发 。
那么RDD上的哪些操作是宽依赖,哪些操作是窄依赖呢?
其实仔细想想很好区分,对于map、filter这种不需要Shuffle的操作都是窄依赖,而groupBy、reduceBy等需要Shuffle聚合的操作都是宽依赖。
通过Transformation操作,RDD之间将会产生依赖关系,基于RDD上的操作与依赖关系 将会形成一张逻辑执行图 来描述本次任务的计算过程。
什么意思呢?
在RDD上进行的Transformation操作都是惰性执行的,意思就是只有数据真正用到的时候(Action操作)才会进行Transformation操作。
例如以下RDD的操作:
| |
也就是说,count之前,我们写的计算逻辑其实只是在 画一个逻辑图,只有真正使用到了count的时候,整个逻辑图才会被触发并执行计算逻辑。
这么做的原因要归咎到RDD的计算模型,当rdd中出现action操作的时候,spark将会生成一个job,并根据rdd的依赖关系画出一张逻辑执行图。
费劲心机画出了逻辑图之后再划分物理图时将会有最关键的作用。
3.物理执行图
从RDD上得到逻辑执行图之后,执行计算任务前期的准备工作就都完成了,现在我们来详细讨论一下Spark是如何 拆分、分发计算逻辑的。
Spark将会划分逻辑图从而生成物理执行图,表现形式为 DAG有向无环图,RDD的执行模型将根据物理图的划分而展开。
现在我们知道,基于逻辑执行图,由于RDD之间的依赖关系被明显的划分为了两种:
- 对于完全依赖
窄依赖,可以完全不管其他RDD或者其他分区的执行进度,直接一条走到底的 - 对于部分依赖
宽依赖,需要父RDD不同分区中的数据,所以他一定是等到所有父RDD计算完毕之后才会执行的
基于逻辑执行图和对应的依赖关系,Spark可以明显的 划分出Stage:
- 从逻辑图的最后方开始创建Stage
- 遇到完全依赖则加入当前Stage
- 遇到部分依赖则新建一个Stage
由此对整个逻辑图进行Stage的划分。这就是Spark对于计算逻辑的组织和拆分方式。
那么这么做有什么好处呢?
基于Stage的独立性,Spark实现了 Pipeline的计算方式。且由于 Stage内部的操作只有完全依赖,它可以毫无顾忌的建立 回溯机制:当一个分区数据计算失败或者丢失,可以直接从父RDD对应的分区中恢复,而不是重新计算整个父RDD。
如果所有操作都是立即执行的话,那么处理流程应该是这样子的:
| |
注意,这种模式下,每个步骤都需要将 全量的数据集加载到内存中操作 这是毋庸置疑的,每个操作都要等待前一个操作全部处理完毕。
作为对比,我们再来看Pipeline的计算模式:
| |
数据是作为流一条条从管道的开始一路走到结束,每个Stage都是一条独立的管道。最为直观的好处就是:不需要加载全量数据集,上一次的计算结果可以马上丢弃。
全量数据集其实是一个很恐怖的东西,全世界都在避免它。所以某种意义上来看,如果没有Shuffle过程,Spark所需要内存其实非常小,一条数据又能占多大空间。
第二,如果不是Pipeline的方式,而是马上触发全量操作,势必需要一个中间容器来保存结果,其实这里就又回到MapReduce的老路,效率很低。
现在我们来考虑 不根据RDD的依赖关系来划分Stage的前提下,两种比较极端的情况:
1、整个逻辑图作为一个Stage
- 一个Job只包含一个Stage,数据一路从头走到尾,什么中间结果都不需要保存
- 如果RDD之间都是 完全依赖 的话这是最完美的场景
- 缺陷:
- 在Shuffle操作符处(即部分依赖的产生处),只能通过一个Task来处理所有分区的数据
- 多个Task情况下没有办法各自感知Shuffle过程中所需要的数据状态
- 严重影响计算效率
2、每个RDD的操作都作为一个Stage
- 各个操作都需要进行全量计算,其实就相当于MapReduce
- 缺陷:严重影响计算效率
可以看到,Spark通过RDD之间的依赖关系来划分逻辑执行图形成一个个独立的Stage,并通过Stage来实现Pipeline的计算模式。
计算逻辑拆分后,通过Pipeline的执行将计算逻辑分发到各个节点,并最大程度保证计算的效率。
综上,基于逻辑执行图能做的事情有: 1、划分Stage 2、执行Pipeline 3、建立回溯机制
根据RDD之间的依赖关系来划分Stage解决了以下问题: 1、实现Pipeline,不需要保留中间计算结果 2、计算保持高效,Task分布均衡
至此,Spark主要的 计算逻辑拆分与分发 步骤大概介绍完毕。
与之相对的,一段Spark代码,或者一个Spark程序,运行起来之后是什么样子的,代码是如何被调度执行的,应该在开发的阶段就能在脑子里形成一个执行图。
充分了解程序运行的背后发生了什么是保证系统稳定高效运行的关键,这点放在哪里都是真理。
Shuffle过程与管理
1. Shuffle总览
和之前看到的MapReduce Shuffle过程相对比。二者在高级别上来看别没有多大区别,都是将mapper中的数据进行partition之后送到不同的reducer中,reducer以内存为缓存边拉取数据边计算。
但是在具体实现的低级别角度上两者区别还是比较大的,MapReduce阶段划分明显,Spark中没有明显的划分。
MapReduce中的Mapper即为Spark中的 ShuffleMapTask,而Reduce对应的可能是ShuffleMapTask或者ResultTask。
Spark各个阶段通过RDD的算子体现出来,具体Shuffle过程可以分为:
- Shuffle Write
- Shuffle Read
Write过程其实很简单,根据之前划分的Stage,每个Stage的final task的结果将会写磁盘,和MapReduce一样,有多少个分区数就会写多少个文件。
后续的Stage将会通过网络来fatch各自对应的数据文件。
Read过程需要解决几个问题:
什么时候fetch数据:依赖的stage中所有ShuffleMapTask都执行完之后才进行fetch,迎合pipeline的思想何获得数据位置:ShuffleMapTask结束之后都会想Driver端汇报数据存放位置,ResultTaskfetch数据时都会向Driver查询需要fetch的数据在哪里,Driver端有比较复杂的实现机制fetch的数据怎么存:刚fetch过来的数据存放在softBuffer中,计算之后的数据可以根据策略选择存放在内存或者内存+磁盘中
和fetch过程的计算和MapReduce也不一样:
- Spark:
边fetch边计算,因为是无序的,所有没有必要要求所有数据都获取之后才进行计算 - MapReduce:
MapReduce中强制要求数据有序之后才进行reduce操作,所以MapReduce是一次性fetch所有数据之后才计算
总结一下,与MapReduce相比:
- Height Level:无太大区别,将mapper中的数据进行partition之后送到不同的reducer中
- Low Level:实现差别较大,MapReduce阶段划分明显,Spark中没有明显的划分
2. Shuffle Manage
Spark 中负责 Shuffle 过程管理的是 ShuffleManager,它接管了 Shuffle Read、Shuffle Write 过程中的 执行、计算和处理 相关的实现细节。
比如 Write 过程中怎么组织数据写入磁盘,Read 过程中怎么拉取数据和保存数据。
ShuffleManager 是一个接口,主要有两种实现:
- HashShuffleManager:Spark 1.2之前默认使用,会产生大量的中间磁盘文件,进而由大量的磁盘IO操作影响了性能。
- SortShuffleManager:每个Task在进行Shuffle操作时,虽然也会产生较多的临时磁盘文件,但是最后会将所有的临时文件合并(merge)成一个磁盘文件,因此每个Task就只有一个磁盘文件。在下一个stage的Shuffle read task拉取自己的数据时,只要根据
索引读取每个磁盘文件中的部分数据即可。
HashShuffleManager
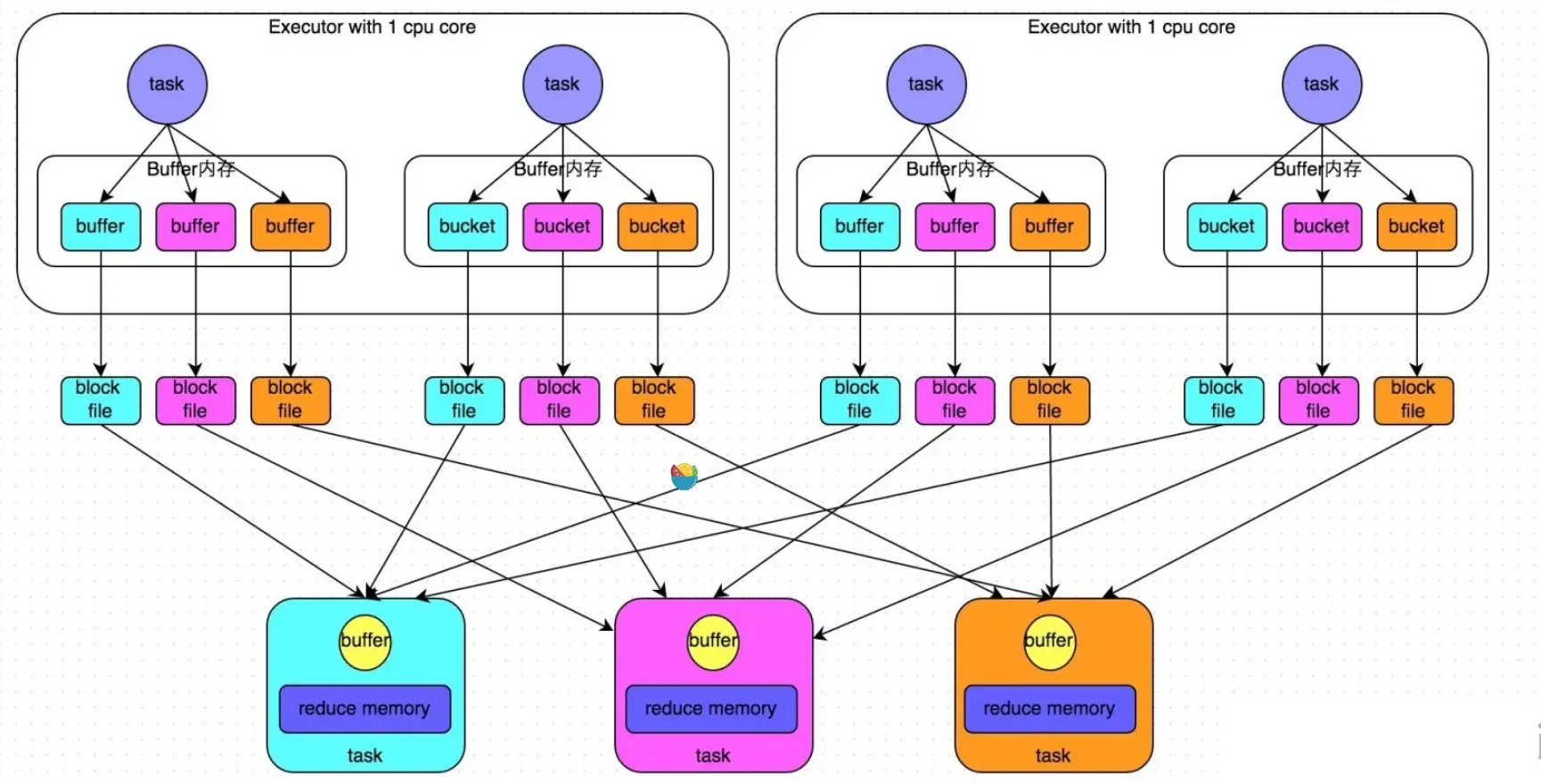
为了简单的说明,这里假设我们的 Executor 可用的CPU核心数只有一个,无论 Executor 上有分配了多少个Task,同一时间只能执行一个Task。
在 Shuffle Write 阶段,Executor 的在依次执行每个Task时,HashShuffleManager 都会对Task 中的所有数据的key执行相应的hash运算,hash的参数是下游Stage的 Task数量。通过这hash映射之后,每个key都会有一个对应的结果值,根据hash的结果值来写文件(这个过程中会经过一段内存的缓冲区,缓冲区满了之后写入磁盘),相同结果的数据写到一个文件中。
这样一来,上游每个Task中,都会根据下游Stage的Task数量 产生对应数量的文件,相同key的数据肯定在同一份文件中,一份文件中可能会有多个key的数据。下游stage计算数据时,只需要拉取这个文件的所有数据即可进行计算。在这个过程中,会边拉取边计算,每个Task也会有自己的缓冲区,每次只取buffer大小的数据通过内存中的Map进行聚合,反复操作直至数据获取完毕。
么描述大家可能还会觉得合情合理,那么我们从产生的总文件数的角度来看呢?
假设当前Stage有200个Task需要执行,下游Stage有100个Task,按照我们刚刚描述的过程来看,产生的总文件数为:200 * 100 = 20000 个。
这是一个非常惊人的数字,我们都知道 磁盘的IO 一直是程序执行的瓶颈之一,我们在执行程序的时候都会尽可能的避免写磁盘操作。而现在,一个 Shuffle Write 过程就会产生成千上万个文件,注定了这个程序不会快到哪里去。
工作流程如下图所示:
那么有没有优化方式呢?肯定是有的。
在使用 HashShuffleManager 的时候,我们可以设置一个参数 spark.Shuffle.consolidateFiles 该参数默认值为false,将其设置为true即可开启优化机制。强烈建议设置为true,为啥呢?我们来解释解释。
consolidate机制最重要的功能就是 同一个CPU 允许不同的task复用同一批磁盘文件,这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升Shuffle write的性能。
之前的流程中,每个Task都会创建n个文件,Task之间是互相隔离的。而在 consolidate机制 中Task之间是可以复用文件的,因为同一个key的数据可能是分布在不同的Task上处理的。
简单来说,因为Task之间的数据文件可以复用,一个cpu核心只会创建和下游Stage的Task数量一样多的文件数,同一个cpu核心中处理的所有task都会重复使用同一批文件。
总结为:
- consolidate=false:文件数量由 上游Stage任务数(不同的任务可能会被同一个cpu处理) * 下游Stage任务数 决定
- consolidate=true:文件数量由 上游处理任务的CPU核心数(一个cpu可能会处理多个任务) * 下游Stage任务数 决定
还是我们之前举的例子,假设当前Stage有200个Task需要执行,下游Stage有100个Task,如果此时我们有10个Executor(每个1core),那么总文件数为: 10(cpu核心数)* 100(下游Task数量) = 200 个。
由此可见,当开启了 consolidate 机制后,Executor 的cpu核心数越多,在提供处理并行度的同时,Shuffle Write 产生的文件数就越多,这点需要注意。
Shuffle Read 阶段并没有变化,都是直接拉取自己所需要的那份数据进行计算。
consolidate机制下,工作流程如下:

SortShuffleManager
经过前面的介绍之后,我们知道使用 HashShuffleManager 时开启consolidate机制可以减少很多文件的产生,提高 Shuffle Write 效率。
无论 consolidate机制 是否开启,HashShuffleManager 所产生的文件数都与下游Stage的Task数量有关系。
现在我们再来看另外一种 Shuffle管理机制,SortShuffleManager。
通过 SortShuffleManager 这个名字大家可以知道,这是一个排序的Shuffle管理器(HashShuffleManager为无序)。
Shuffle Write 的具体执行过程如下:
- 每个Task将Shuffle的数据写入自己的buffer内存缓冲区中,每条数据写入时都会判断是否超出阈值
- 超出使用阈值则触发刷写,将数据一批批的写入磁盘中
- 写入磁盘前会根据key对内存中的数据进行排序
- 排完序后的数据根据批次大小(默认10000)依次写入磁盘中
- Task数据处理结束后,将之前刷写的所有文件读取,合并之后重新写入一个大文件中
- 因为一个Task处理的数据可能对应下游多个Task需要处理的数据
- 所以此过程会创建索引文件标记下游各个Task对应的数据在文件中的start offset与end offset
- 由于需要标记下游各个Task所需要的数据偏移量,所以需要进行sort排序之后才可写入
从以上过程中可以看出,和 HashShuffleManager 一样 SortShuffleManager 的每个Task也会创建很多文件,不同的是 HashShuffleManager 中每个Task创建的文件数和下游的Stage任务数一致,而 SortShuffleManager 则是 按照自己的buffer内存空间大小刷写的文件块,并且最后还会做一次大合并,一个Task只对应一个文件。
文件数量由 上游Stage的Task数量 决定。
执行流程如下:

除此之外,SortShuffleManager 还有另外一种 bypass 的执行模式。
当 Shuffle map task数量小于 spark.Shuffle.sort.bypassMergeThreshold 的值,且不是聚合类的Shuffle算子(比如reduceByKey),比如 join 等操作时将会触发。
此时task会为每个下游task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。
最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并 创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,Shuffle read的性能会更好。
而该机制与普通SortShuffleManager运行机制的不同在于:
- 第一,磁盘写机制不同;
- 第二,不会进行排序。
也就是说,启用该机制的最大好处在于,Shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
内存模块
Spark是用Scala开发完成的,也是一个运行在JVM体系上的系统性框架,所以 Spark的内存模型也是基于Java虚拟机来的。
基本模型就是:堆、栈、静态代码块和全局空间,在虚拟机的内存模型上Spark将内存做了二次划分。
作为一个严重依赖内存进行数据计算的系统来说,内存管理模块 是Spark中极其重要的一部分。
1. 内存划分
从性质上看,Executor 可使用的内存空间分为两种:堆内、堆外。
堆内内存即直接通过 spark.executor.memory 或者 -–executor-memory 设置分配得到,属于一定会有值的强制性配置。
而堆外内存则是一种可选性配置,默认不使用,通过配置 spark.memory.offHeap.enabled 参数启用,由 spark.memory.offHeap.size 参数设定堆外空间的大小。
堆外内存将会 存储经过序列化的二进制数据。一定程度上会减少不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。
从内存区域上看,内存大致可以划分为三个模块(堆外内存没有 Execution 的空间):
- Storage:RDD缓存、Broadcast等数据空间。
- Execution:Shuffle过程使用的内存。
- Other:用户定义的数据结构、Spark内部元数据等其他内存空间。
2. 内存管理
静态内存管理
静态内存管理为 Spark 1.6 之前默认使用的管理方式。 忽略
统一内存管理

在内存结构总体不变的情况下,Spark 1.6 之后引入了新的内存管理机制,统一内存管理。
和静态内存管理相比,统一内存管理主要的变化点在于:
- 增加系统预留的内存空间
- 各个区域初始分配的默认值重新调整
- Storage和Execution两个区域之间不再是固定大小,而是 动态调节
总堆内内存的基础上,先扣除 给系统的预留空间(默认300M),剩下的为可用内存总大小。
- 注意:
spark.memory.storageFraction统一内存管理的参数spark.storage.memoryFraction静态内存管理的参数
(deprecated) This is read only if spark.memory.useLegacyMode is enabled. Fraction of Java heap to use for Spark’s memory cache. This should not be larger than the “old” generation of objects in the JVM, which by default is given 0.6 of the heap, but you can increase it if you configure your own old generation size.
在可用内存总大小的基础上,划分两大块:
- 统一内存(Unified Memory):Storage、Execution共同使用的内存,默认值 0.75(2.0以后为0.6),由
spark.memory.fraction控制 - Storage:默认为0.5,占统一内存的50%,由
spark.memory.storageFraction控制。主要用于存储 spark 的 cache 数据,例如RDD的缓存、unroll数据; - Execution:默认为0.5,占统一内存的50%,等于
1 - spark.memory.storageFraction。主要用于存放 Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据; - 用户内存(User Memory):默认为0.4,占可用总内存的40%, 等于
1 - spark.memory.fraction。主要用于存储 RDD 转换操作所需要的数据,例如 RDD 依赖等信息; - 预留内存(Reserved Memory): 系统预留内存,会用来存储Spark内部对象。
可以看到,在统一内存管理中,Storage和Execution被划入一块大内存池中进行统一管理。
这样做的好处是,Storage和Execution 的内存空间用户可以不用自己那么操心去优化、调整。
当有一方的内存不够用时,将会到另外一方去「借」一些内存回来用,达到 动态内存分配与调整 的效果。
在 Spark 1.6 之后的版本中默认不再使用 静态内存管理 的方式,但是可以通过设置 spark.memory.userLegacyMode 的值(true/false,默认false)来选择内存管理方式。
其中最重要的优化在于动态占用机制,其规则如下:
- 设定基本的存储内存和执行内存区域(spark.storage.storageFraction参数),该设定确定了双方各自拥有的空间的范围。
- 双方的空间都不足时,则存储到硬盘;若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的Block)。
- 执行内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后“归还”借用的空间。
- 存储内存的空间被对方占用后,无法让对方“归还”,因为需要考虑Shuffle过程中的很多因素,实现起来较为复杂。

凭借统一内存管理机制,Spark在一定程度上提高了堆内和堆外内存资源的利用率,降低了开发者维护Spark内存的难度,但并不意味着开发者可以高枕无忧。 譬如,所以如果存储内存的空间太大或者说缓存的数据过多,反而会导致频繁的全量垃圾回收,降低任务执行时的性能,因为缓存的RDD数据通常都是长期驻留内存的。所以要想充分发挥Spark的性能,需要开发者进一步了解存储内存和执行内存各自的管理方式和实现原理。
Spark性能优化
1. 开发调优
代码开发,是执行Spark任务的第一步,同时也是优化Spark任务的第一个入手点,良好的 RDD lineage、高性能的算子操作、不同高级特性的组合使用,都能够给Spark任务带来巨大的提升空间。
开发出优秀的Spark程序,需要你熟悉Spark的各种API和特性。其中最重要的一点我们在逻辑执行图小节中提到过:开发Spark程序其实就是在画图。
如何能够把这个图快速画出来的同时还能画好看,就是你需要考虑的,这就是考验Spark开发的基本功。
- RDD复用
和其他任何程序中 变量复用 一样,在Spark程序中创建并使用RDD也要贯彻这个思想。
在编码的时候,RDD和任何单机程序一样,本身只是作为一个普通的变量对象存在,不同的是单机变量的创建会消耗内存,而RDD的创建会 消耗磁盘、内存与算力等更多方面的资源(想想RDD创建之后的使用过程,是不是这样呢)。
所以要把RDD的创建和使用当做一个 需要消耗高昂费用的动作 来谨慎使用,从代码的源头节约与优化程序空间与效率。
有的同学在开发Spark程序的时候,可能在业务逻辑1创建了一个RDD1,经过各种Transformation以及最后的Action操作之后,开始处理业务逻辑2,又在相同的数据源上创建了RDD2,然后继续写业务逻辑代码。
一般来讲,相同的数据源的RDD 只允许创建一次,不要创建相同的RDD,保证代码的整洁性。
在RDD的lineage过程中,如果有多个业务重复使用某个lineage的计算过程,则 应该将其抽出作为一个独立的中间RDD使用,尽可能复用相同的RDD。
无论是数据源RDD还是中间RDD,如果被反复多次使用,则应该考虑将其做 缓存持久化操作。
可以看到,如果没有对业务逻辑有比较清晰的了解,开发人员很难从繁杂的计算过程中提取出可以复用甚至进行缓存操作的代码块,无法优化到点。
另外,在考虑对RDD持久化操作时,应该针对 可用硬件资源、RDD数据量、程序时效性等要求 选择不同的缓存策略(详见「内存模块」小节)。
总结:
- 相同的数据源的RDD 只允许创建一次
- 多个业务逻辑反复使用同一个lineage 应该将其抽出作为一个独立的中间RDD使用
- 任何被多次重复使用的RDD应该考虑将其做 缓存持久化操作
例子:
- 避免创建重复的RDD
| |
- 尽可能复用同一个RDD
| |
- 对多次使用的RDD进行持久化
| |
- 尽量避免使用shuffle类算子
如果有可能的话,要尽量避免使用shuffle类算子。因为Spark作业运行过程中,最消耗性能的地方就是shuffle过程。shuffle过程,简单来说,就是将分布在集群中多个节点上的同一个key,拉取到同一个节点上,进行聚合或join等操作。比如reduceByKey、join等算子,都会触发shuffle操作。
shuffle过程中,各个节点上的相同key都会先写入本地磁盘文件中,然后其他节点需要通过网络传输拉取各个节点上的磁盘文件中的相同key。而且相同key都拉取到同一个节点进行聚合操作时,还有可能会因为一个节点上处理的key过多,导致内存不够存放,进而溢写到磁盘文件中。因此在shuffle过程中,可能会发生大量的磁盘文件读写的IO操作,以及数据的网络传输操作。磁盘IO和网络数据传输也是shuffle性能较差的主要原因。
因此在我们的开发过程中,能避免则尽可能避免使用reduceByKey、join、distinct、repartition等会进行shuffle的算子,尽量使用map类的非shuffle算子。这样的话,没有shuffle操作或者仅有较少shuffle操作的Spark作业,可以大大减少性能开销。 Broadcast与map进行join代码示例
| |
使用map-side预聚合的shuffle操作 如果因为业务需要,一定要使用shuffle操作,无法用map类的算子来替代,那么尽量使用可以map-side预聚合的算子。 所谓的map-side预聚合,说的是在每个节点本地对相同的key进行一次聚合操作,类似于MapReduce中的本地combiner。map-side预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的key都被聚合起来了。其他节点在拉取所有节点上的相同key时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘IO以及网络传输开销。通常来说,在可能的情况下,建议使用reduceByKey或者aggregateByKey算子来替代掉groupByKey算子。因为reduceByKey和aggregateByKey算子都会使用用户自定义的函数对每个节点本地的相同key进行预聚合。而groupByKey算子是不会进行预聚合的,全量的数据会在集群的各个节点之间分发和传输,性能相对来说比较差。 比如如下两幅图,就是典型的例子,分别基于reduceByKey和groupByKey进行单词计数。其中第一张图是groupByKey的原理图,可以看到,没有进行任何本地聚合时,所有数据都会在集群节点之间传输;第二张图是reduceByKey的原理图,可以看到,每个节点本地的相同key数据,都进行了预聚合,然后才传输到其他节点上进行全局聚合。
使用高性能的算子
使用reduceByKey/aggregateByKey替代groupByKey 详情见“原则五:使用map-side预聚合的shuffle操作”。
使用mapPartitions替代普通map mapPartitions类的算子,一次函数调用会处理一个partition所有的数据,而不是一次函数调用处理一条,性能相对来说会高一些。但是有的时候,使用mapPartitions会出现OOM(内存溢出)的问题。因为单次函数调用就要处理掉一个partition所有的数据,如果内存不够,垃圾回收时是无法回收掉太多对象的,很可能出现OOM异常。所以使用这类操作时要慎重!
使用foreachPartitions替代foreach 原理类似于“使用mapPartitions替代map”,也是一次函数调用处理一个partition的所有数据,而不是一次函数调用处理一条数据。在实践中发现,foreachPartitions类的算子,对性能的提升还是很有帮助的。比如在foreach函数中,将RDD中所有数据写MySQL,那么如果是普通的foreach算子,就会一条数据一条数据地写,每次函数调用可能就会创建一个数据库连接,此时就势必会频繁地创建和销毁数据库连接,性能是非常低下;但是如果用foreachPartitions算子一次性处理一个partition的数据,那么对于每个partition,只要创建一个数据库连接即可,然后执行批量插入操作,此时性能是比较高的。实践中发现,对于1万条左右的数据量写MySQL,性能可以提升30%以上。
使用filter之后进行coalesce操作 通常对一个RDD执行filter算子过滤掉RDD中较多数据后(比如30%以上的数据),建议使用coalesce算子,手动减少RDD的partition数量,将RDD中的数据压缩到更少的partition中去。因为filter之后,RDD的每个partition中都会有很多数据被过滤掉,此时如果照常进行后续的计算,其实每个task处理的partition中的数据量并不是很多,有一点资源浪费,而且此时处理的task越多,可能速度反而越慢。因此用coalesce减少partition数量,将RDD中的数据压缩到更少的partition之后,只要使用更少的task即可处理完所有的partition。在某些场景下,对于性能的提升会有一定的帮助。
使用repartitionAndSortWithinPartitions替代repartition与sort类操作 repartitionAndSortWithinPartitions是Spark官网推荐的一个算子,官方建议,如果需要在repartition重分区之后,还要进行排序,建议直接使用repartitionAndSortWithinPartitions算子。因为该算子可以一边进行重分区的shuffle操作,一边进行排序。shuffle与sort两个操作同时进行,比先shuffle再sort来说,性能可能是要高的。
广播大变量
使用Kryo优化序列化性能
优化数据结构
2. 资源调优
了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了。所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使用的效率,从而提升Spark作业的执行性能。以下参数就是Spark中主要的资源参数,每个参数都对应着作业运行原理中的某个部分,我们同时也给出了一个调优的参考值。
num-executors
- 参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
- 参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
executor-memory
- 参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
- 参数调优建议:每个Executor进程的内存设置4G
8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的内存量最好不要超过资源队列最大总内存的1/31/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
executor-cores
- 参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
- 参数调优建议:Executor的CPU core数量设置为2
4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/31/2左右比较合适,也是避免影响其他同学的作业运行。
driver-memory
- 参数说明:该参数用于设置Driver进程的内存。
- 参数调优建议:Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
spark.default.parallelism
- 参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
- 参数调优建议:Spark作业的默认task数量为500
1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的23倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
spark.memory.memoryFraction
注意: 一下两个参数是在spark1.6 静态内存管理的时候有效,现在spark2 以上的版本使用的是同意内存管理,参数已经失效,spark 会自己动态关系,storage execution 内存。
- 参数说明:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
- 参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
spark.shuffle.memoryFraction [deprecated after spark1.6]
- 参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
- 参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。 资源参数的调优,没有一个固定的值,需要同学们根据自己的实际情况(包括Spark作业中的shuffle操作数量、RDD持久化操作数量以及spark web ui中显示的作业gc情况),同时参考本篇文章中给出的原理以及调优建议,合理地设置上述参数。 demo
| |
3. 数据倾斜调优
代码写好了,程序跑的资源也经过精心调配之后设置好了,没有其他意外情况的话,你的Spark程序已经能够正常的跑在集群上。
但是别以为这样就结束了,这仅仅是Spark程序生命周期的开始。
为了给你的程序保驾护航,你还需要时刻关注 新上线的应用程序的执行情况是否健康、是否如你所愿如你所想。
应用程序的执行情况你都可以在 Spark或者Yarn的WebUI 上查看到,有非常详细的执行信息。
我们现在来讨论一个 可能是导致程序执行缓慢甚至异常 的最大罪魁祸首: 数据倾斜。
什么是数据倾斜呢?
就是 绝大多数数据(比如80%以上甚至更多)都被分配到 绝少数的节点 上执行(比如20%甚至更少)。
这么一来,意味着剩下绝大多数的节点都没处理或者没怎么处理数据,处于空闲状态。而 少数节点则一直处理非常忙碌的状态,任务处理需要排队,节点完成计算任务耗时非常长,其他完成任务的节点就在旁边看热闹,但是 只有等所有节点都完成了计算任务整个程序才能算完成。
例如,总共有1000个task,990个task都在10分钟之内执行完了,但是剩余10个task却要三、四个小时,整个程序的执行时间由最长的那个task决定(反过来的木桶效应)。
同时,因为某些节点上处理的数据量太多,根据不同的业务代码操作,可能还会出现某些节点在Shuffle过程或者数据处理过程出现OOM异常导致程序失败。
简单来讲,就是 几颗老鼠屎坏了一锅粥。
导致数据倾斜的原因有很多,但是其本质都是一样的:在Shuffle等需要通过网络读写数据的过程中,因为数据key分布不均匀,导致大部分数据被集中获取到少部分节点上。
数据倾斜的情况可以在WebUI上的Stages、Executors页面中观察到,这也就是为什么我们要求对于初次上线的应用,需要时刻关注新上线的应用程序的执行情况是否健康、是否如你所愿如你所想。
在Web界面中,有哪些Stage,Stage中有哪些Task,各个Task处理的数据量和执行计算的时间等等,这些你都可以很清晰的看到。
如果发现你的应用中有存在有 几个Task处理的数据量明显比其他Task要大很多,而且还在不停的处理数据,而其他Task已经执行完毕,那么你就是遇到了数据倾斜的问题。
那么如果我们确定了程序中存在数据倾斜的情况,该如何处理呢?
根据数据倾斜产生的原因,我们可以在 不同的切入点使用不同的处理策略。
定位代码与数据问题
在Web界面上,我们可以直观的获得 发生数据倾斜的Stage对应的代码行数,但这个行数并不能精准直接定位到发生数据倾斜的代码,因为它显示的是当前Stage开始执行的代码行数。
由于数据倾斜只有可能在Shuffle过程中发生,所以 导致数据倾斜的一定是会产生Shuffle过程的算子,比如groupByKey、reduceByKey、aggregateByKey、join、distinct、repartition等等。
所以,你只需要在Stage所在的行数向上查找Shuffle操作符,那么其就是导致数据倾斜的罪魁祸首。
找到问题代码之后,需要做的事情很明显了吧?优化之。
此时我们需要统计一下该Shuffle操作符所使用的数据源,观察各个数据源的 key分布情况(如每个key有多少数据量),以及导致数据倾斜的key在哪里、都有哪些。
根据数据情况与你对业务的理解,使用「开发调优」中算子优化提到的技巧,尽量这个Shuffle操作的影响降到最低。
处理源头数据
如果该Shuffle操作符无法避免,代码层面上无法做太多优化,那么此时可以考虑 预先处理数据源。
先根据数据源key的分布情况或者分区分布情况,针对性的做一次repartition操作,重新存储,后续所有用到该数据源的程序都不会有数据倾斜的问题。
但是重分区预处理过程中仍然会存在数据倾斜问题而导致预处理过程缓慢。
如果该数据源只有当前程序使用,那么这个重分区预处理的操作就相当于在读取数据源的时候调用了repartition重分区、或者使用类似reduceByKey(500)调整并行度,实际上并没有起到多少作用。
所以,重分区预处理的方式只有在 一个数据源被n多个程序使用的时候比较有价值,使用的程序越多性价比越高,否则就是治标不治本,效果有限。
预聚合
如果前面两种方式都无法解决你的问题,而且 产生数据倾斜的Shuffle操作符是聚合类的(group、reduce、distinct)等,那么你可以尝试使用 预聚合 的方式。
还记得Mapreduce的Combiner吗,还记得reduceByKey和groupByKey的区别吗,不记得的话建议浏览一下「开发调优」中算子优化技巧。
Mapreduce的Combiner和Spark中的reduceByKey都会在各个节点的本地做一次预聚合。
类似的,如果存在某个key占据了绝大部分的数据量的话,我们也可以 手动采用预聚合的方式来分散热点数据并执行本地预聚合。
假设我们现在有1000w的数据,其中800w的数据都是相同的key,此时我们要做聚合操作,默认情况下800w数据会到同一个Task中处理,这肯定是无法接受的。
- 怎么手动做预聚合呢?
首先我们可以在这800w的key之前 根据任意hash算法添加固定长度的随机前缀。
在第一轮聚合时,这个热点key将会被打散到各个节点上去计算。
之后将key上的固定长度前缀去除,执行第二轮聚合操作。
因为经过第一轮聚合之后 热点key的数据已经被处理很多了,所以在第二轮聚合的时候可以比较轻松的处理。
当然如果在第二轮聚合的时候仍然有很大的热点问题,那么理论上可以 继续无限做预聚合处理。
但是预聚合的缺陷也很明显,只能优化聚合类的操作,如果是join等关联类的Shuffle操作则无法优化。
使用广播变量代替join
那么碰到join类的算子且发生了数据倾斜该如何处理呢?
其实我们在「开发调优」中已经提到过解决方式了,就是 使用广播变量来代替join操作。
但是这个方法也有很多限制,就是 只能应用于大表 join 小表的情况。
多种方案组合使用
如果以上的方案都没有能够解决你的问题,那么你可以尝试着将多种方案整合起来一起使用,因为在复杂的业务中,Shuffle操作符可能有很多,那么对应的可能产生数据倾斜的地方也有很多。
所以需要开发人员能够根据 业务逻辑、数据状态、代码编写 等方面能够根据不同的情况组合不同的方案来实施优化。
4. shuffle调优
在上一节中我们着重介绍了如何针对「数据倾斜」这一情况进行优化。
除了数据倾斜可以优化之外,Shuffle过程中仍然有许多地方可以优化。但是要记住,影响Spark程序性能的主要因素还是在于 代码开发、资源参数与数据倾斜等,对Shuffle的调整优化可能仅仅是 锦上添花 而不是雪中送炭。
所以开发人员的重点应该放在前面几个部分,都优化完了之后可以考虑对Shuffle过程进行优化。
对Shuffle的优化主要是通过调整一些Shuffle相关的参数来实现,你可以根据你的使用情况和经验对以下参数进行调整:
spark.Shuffle.file.buffer
- 默认值:32k
- 参数说明:用于设置Shuffle write task的BufferedOutputStream的buffer缓冲大小。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。
- 调优建议:如果作业可用的 内存资源较为充足 的话,可以 适当增加这个参数的大小,从而减少Shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,进而提升性能。
spark.reducer.maxSizeInFlight
- 默认值:48m
- 参数说明:用于设置Shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。
- 调优建议:如果作业可用的 内存资源较为充足 的话,可以 适当增加这个参数的大小,从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。
spark.Shuffle.io.maxRetries
- 默认值:3
- 参数说明:Shuffle read task从Shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败。
- 调优建议:对于那些包含了 特别耗时的Shuffle操作的作业,建议 增加重试最大次数(比如60次),以避免 由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败,主要提升大型任务的执行稳定性。
spark.Shuffle.io.retryWait
- 默认值:5s
- 参数说明:具体解释同上,该参数代表了每次重试拉取数据的等待间隔,默认是5s。
- 调优建议:建议 加大间隔时长(比如60s),以增加Shuffle操作的稳定性。
spark.Shuffle.manager
- 默认值:sort
- 参数说明:该参数用于设置ShuffleManager的类型。
- 调优建议:由「Shuffle过程与管理」中可以知道,SortShuffleManager默认会对数据进行排序,如果程序中需要排序,那么使用默认即可;如果程序中不需要排序,那么建议 增大bypass的阈值以触发bypass机制或者将manager调整为hash,避免排序带来的开销,同时提供较好的磁盘读写性能。
spark.shuffle.sort.bypassMergeThreshold
- 默认值:200
- 参数说明:当manager为sort,且Shuffle read task的数量小于这个阈值时,将会使用bypass机制。
- 调优建议:使用sort manager时,如果不需要排序,那么就适当增加这个值,大于Shuffle read task的数量。
spark.shuffle.consolidateFiles
- 默认值:false
- 参数说明:如果使用hash manager,该参数有效。如果设置为true,那么就会开启 consolidate机制,可以极大地减少磁盘IO开销,提升性能。
- 调优建议:在不需要排序的情况下,除了使用sort manager触发bypass机制外,使用 hash manager + consolidate机制也是一个高性能的选择,建议使用此组合。 更多参考: 美团spark调优