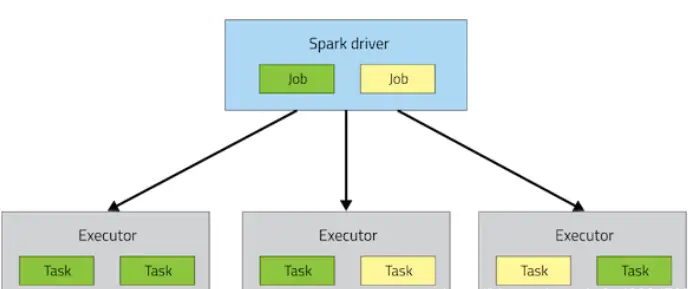
简介
当一个Spark应用提交到集群上运行时,应用架构包含了两个部分:
Driver Program(资源申请和调度Job执行)Executors(运行Job中Task任务和缓存数据),两个都是JVM Process进程
Driver程序运行的位置可以通过–deploy-mode 来指定:
Driver指的是The process running the main() function of the application and creating the SparkContext 运行应用程序的main()函数并创建SparkContext的进程
client: 表示Driver运行在提交应用的Client上(默认)cluster: 表示Driver运行在集群中(Standalone:Worker,YARN:NodeManager)
cluster和client模式最最本质的区别是:Driver程序运行在哪里。
企业实际生产环境中使用cluster 为主要模式。
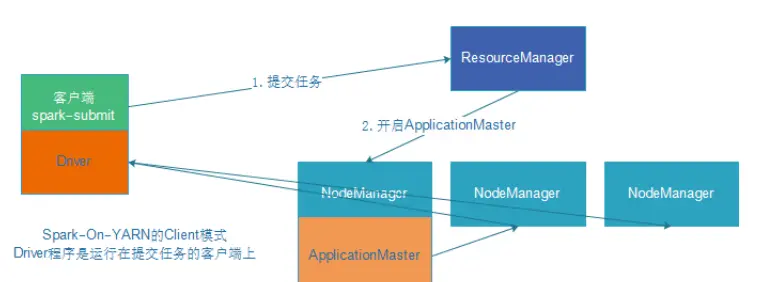
1. Client(客户端)模式
DeployMode为Client,表示应用Driver Program运行在提交应用Client主机上。
示意图:
| |
2.Cluster(集群)模式,生产环境用
DeployMode为Cluster,表示应用Driver Program运行在集群从节点某台机器上.
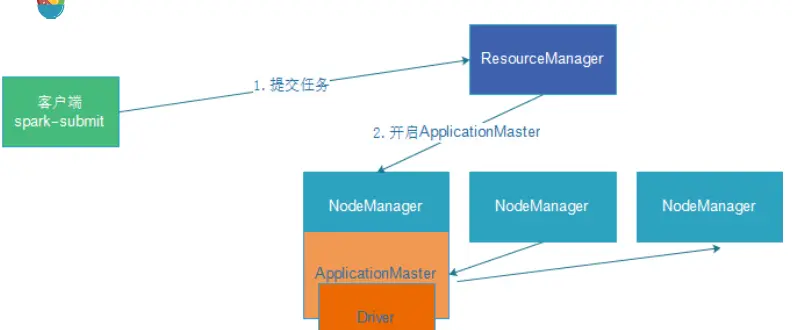
| |
总结:
Client模式和Cluster模式最最本质的区别是:Driver程序运行在哪里。
- Client模式:测试时使用,开发不用,了解即可
- Driver运行在Client上,和集群的通信成本高
- Driver输出结果会在客户端显示
- Cluster模式:生产环境中使用该模式
- Driver程序在YARN集群中,和集群的通信成本低
- Driver输出结果不能在客户端显示
- 该模式下Driver运行ApplicattionMaster这个节点上,由Yarn管理,如果出现问题,yarn会重启ApplicattionMaster(Driver)
3. 两种模式的详细流程图
Client模式图示:
在YARN Client模式下,Driver在任务提交的本地机器上运行。
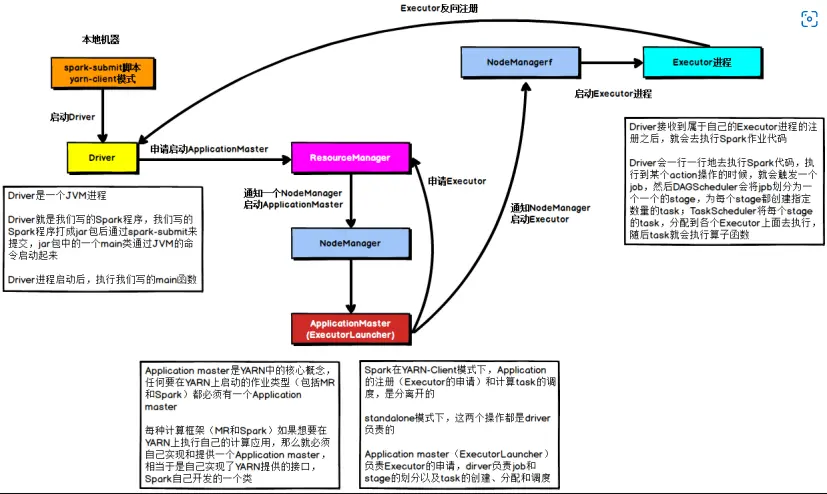
- Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster
| |
- 随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存
| |
- ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程;
- Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数;
- 之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分Stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行。
Cluster 模式示意图
在YARN Cluster模式下,Driver运行在NodeManager Contanier中,此时Driver与AppMaster合为一体。
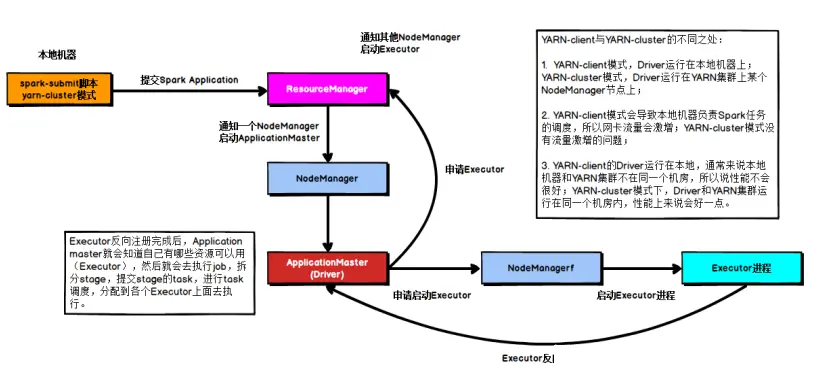
- Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster
| |
- 随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存
| |
- ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程;
- Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数;
- 之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分Stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行。
4. 运行中涉及到的名词
- Application: Appliction都是指用户编写的Spark应用程序,其中包括一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码
- Driver: Spark中的Driver即运行上述Application的main函数并创建SparkContext,创建- SparkContext的目的是为了准备Spark应用程序的运行环境,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭,通常用SparkContext代表Driver
- AppMaster: 控制yarn app运行和任务资源
- Executor: 某个Application运行在worker节点上的一个进程, 该进程负责运行某些Task, 并且负责将数据存到内存或磁盘上,每个Application都有各自独立的一批Executor
- Worker: 集群中任何可以运行Application代码的节点,在Standalone模式中指的是通过slave文件配置的Worker节点,在Spark on Yarn模式下就是NodeManager节点
- Task: 被送到某个Executor上的工作单元,但hadoopMR中的MapTask和ReduceTask概念一样,是运行Application的基本单位,多个Task组成一个Stage,而Task的调度和管理等是由TaskScheduler负责
- Job: 包含多个Task组成的并行计算,往往由Spark Action触发生成, 一个Application中往往会产生多个Job
- Stage: 每个Job会被拆分成多组Task, 作为一个TaskSet, 其名称为Stage,Stage的划分和调度是有DAGScheduler来负责的,Stage有非最终的Stage(Shuffle Map Stage)和最终的Stage(Result Stage)两种,Stage的边界就是发生shuffle的地方
- DAGScheduler: 根据Job构建基于Stage的DAG(Directed Acyclic Graph有向无环图),并提交Stage给TASkScheduler。 其划分Stage的依据是RDD之间的依赖的关系找出开销最小的调度方法
- TASKSedulter: 将TaskSet提交给worker运行,每个Executor运行什么Task就是在此处分配的. TaskScheduler维护所有TaskSet,当Executor向Driver发生心跳时,TaskScheduler会根据资源剩余情况分配相应的Task。另外TaskScheduler还维护着所有Task的运行标签,重试失败的Task
Spark集群中的角色
Driver: 是一个JVM Process 进程,编写的Spark应用程序就运行在Driver上,由Driver进程执行; Master(ResourceManager): 是一个JVM Process 进程,主要负责资源的调度和分配,并进行集群的监控等职责; Worker(NodeManager): 是一个JVM Process 进程,一个Worker运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算。 Executor: 是一个JVM Process 进程,一个Worker(NodeManager)上可以运行多个Executor,Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算,也就是执行我们对RDD定义的例如map、flatMap、reduce等算子操作。