问题目录:
1、决策树的实现、ID3、C4.5、CART(贝壳) 2、CART回归树是怎么实现的?(贝壳) 3、CART分类树和ID3以及C4.5有什么区别(贝壳) 4、剪枝有哪几种方式(贝壳) 5、树集成模型有哪几种实现方式?(贝壳)boosting和bagging的区别是什么?(知乎、阿里) 6、随机森林的随机体现在哪些方面(贝壳、阿里) 7、AdaBoost是如何改变样本权重,GBDT分类树的基模型是?(贝壳) 8、gbdt,xgboost,lgbm的区别(百度、滴滴、阿里,头条) 9、bagging为什么能减小方差?(知乎)
其他问题:
10、关于AUC的另一种解释:是挑选一个正样本和一个负样本,正样本排在负样本前面的概率?如何理解? 11、校招是集中时间刷题好,还是每天刷一点好呢? 12、现在推荐在工业界基本都用match+ranking的架构,但是学术界论文中的大多算法算是没有区分吗?end-to-end的方式,还是算是召回? 13、内推刷简历严重么?没有实习经历,也没有牛逼的竞赛和论文,提前批有面试机会么?提前批影响正式批么? 14、除了自己项目中的模型了解清楚,还需要准备哪些?看了群主的面经大概知道了一些,能否大致描述下?
1、决策树的实现、ID3、C4.5、CART(贝壳)
这道题主要是要求把公式写一下,所以决策树的公式大家要理解,并且能熟练地写出来。这里咱们简单回顾一下吧。主要参考统计学习方法就好了。
ID3使用信息增益来指导树的分裂:

C4.5通过信息增益比来指导树的分裂:

CART的话既可以是分类树,也可以是回归树。当是分类树时,使用基尼系数来指导树的分裂:
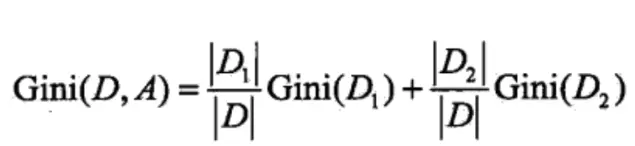
当是回归树时,则使用的是平方损失最小:

2、CART回归树是怎么实现的?(贝壳)
CART回归树的实现包含两个步骤: 1)决策树生成:基于训练数据生成决策树、生成的决策树要尽量大 2)决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时用损失函数最小作为剪枝的标准。
这部分的知识,可以看一下《统计学习方法》一书。
3、CART分类树和ID3以及C4.5有什么区别(贝壳)
1)首先是决策规则的区别,CART分类树使用基尼系数、ID3使用的是信息增益,而C4.5使用的是信息增益比。 2)ID3和C4.5可以是多叉树,但是CART分类树只能是二叉树(这是我当时主要回答的点)
4、剪枝有哪几种方式(贝壳)
前剪枝和后剪枝,参考周志华《机器学习》。
5、树集成模型有哪几种实现方式?(贝壳)boosting和bagging的区别是什么?(知乎、阿里)
树集成模型主要有两种实现方式,分别是Bagging和Boosting。二者的区别主要有以下四点: 1)样本选择上: Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的. Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化.而权值是根据上一轮的分类结果进行调整. 2)样例权重: Bagging:使用均匀取样,每个样例的权重相等 Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大. 3)预测函数: Bagging:所有预测函数的权重相等. Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重. 4)并行计算: Bagging:各个预测函数可以并行生成 Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果.
6、随机森林的随机体现在哪些方面(贝壳、阿里)
随机森林的随机主要体现在两个方面:一个是建立每棵树时所选择的特征是随机选择的;二是生成每棵树的样本也是通过有放回抽样产生的。
7、AdaBoost是如何改变样本权重,GBDT分类树的基模型是?(贝壳)
AdaBoost改变样本权重:增加分类错误的样本的权重,减小分类正确的样本的权重。
最后一个问题是我在面试之前没有了解到的,GBDT无论做分类还是回归问题,使用的都是CART回归树。
8、gbdt,xgboost,lgbm的区别(百度、滴滴、阿里,头条)
首先来看GBDT和Xgboost,二者的区别如下:
1)传统 GBDT 以 CART 作为基分类器,xgboost 还支持线性分类器,这个时候 xgboost 相当于带 L1 和 L2 正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。 2)传统 GBDT 在优化时只用到一阶导数信息,xgboost 则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便 一下,xgboost 工具支持自定义代价函数,只要函数可一阶和二阶求导。 3)xgboost 在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的 score 的 L2 模的平方和。从 Bias-variance tradeoff 角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是 xgboost 优于传统GBDT 的一个特性。 4)Shrinkage(缩减),相当于学习速率(xgboost 中的eta)。xgboost 在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削 弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把 eta 设置得小一点,然后迭代次数设置得大一点。(补充:传统 GBDT 的实现 也有学习速率) 5)列抽样(column subsampling)。xgboost 借鉴了随机森林的做法,支 持列抽样,不仅能降低过拟合,还能减少计算,这也是 xgboost 异于传 统 gbdt 的一个特性。 6)对缺失值的处理。对于特征的值有缺失的样本,xgboost 可以自动学习 出它的分裂方向。 7)xgboost 工具支持并行。boosting 不是一种串行的结构吗?怎么并行的? 注意 xgboost 的并行不是 tree 粒度的并行,xgboost 也是一次迭代完才能进行下一次迭代的(第 t 次迭代的代价函数里包含了前面 t-1 次迭代 的预测值)。xgboost 的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为 block 结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每 个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。 8)可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以 xgboost 还 出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
再来看Xgboost和LightGBM,二者的区别如下:
1)由于在决策树在每一次选择节点特征的过程中,要遍历所有的属性的所有取 值并选择一个较好的。XGBoost 使用的是近似算法算法,先对特征值进行排序 Pre-sort,然后根据二阶梯度进行分桶,能够更精确的找到数据分隔点;但是 复杂度较高。LightGBM 使用的是 histogram 算法,这种只需要将数据分割成不同的段即可,不需要进行预先的排序。占用的内存更低,数据分隔的复杂度更低。 2)决策树生长策略,我们刚才介绍过了,XGBoost采用的是 Level-wise 的树 生长策略,LightGBM 采用的是 leaf-wise 的生长策略。 3)并行策略对比,XGBoost 的并行主要集中在特征并行上,而 LightGBM 的并 行策略分特征并行,数据并行以及投票并行。
9、bagging为什么能减小方差?(知乎)
这个当时也没有答上来,可以参考一下博客:https://blog.csdn.net/shenxiaoming77/article/details/53894973
树模型相关的题目以上就差不多了。接下来整理一些最近群友提出的问题,我觉得有一些可能作为面试题,有一些是准备校招过程中的经验:
10、关于AUC的另一种解释:是挑选一个正样本和一个负样本,正样本排在负样本前面的概率?如何理解?
我们都知道AUC是ROC曲线下方的面积,ROC曲线的横轴是真正例率,纵轴是假正例率。我们可以按照如下的方式理解一下:首先偷换一下概念,意思还是一样的,任意给定一个负样本,所有正样本的score中有多大比例是大于该负类样本的score?那么对每个负样本来说,有多少的正样本的score比它的score大呢?是不是就是当结果按照score排序,阈值恰好为该负样本score时的真正例率TPR?理解到这一层,二者等价的关系也就豁然开朗了。ROC曲线下的面积或者说AUC的值 与 测试任意给一个正类样本和一个负类样本,正类样本的score有多大的概率大于负类样本的score是等价的。
11、校招是集中时间刷题好,还是每天刷一点好呢?
我的建议是平时每天刷3~5道,然后临近校招的时候集中刷。另外就是根据每次面试中被问到的问题,如果有没答上来的,就针对这一类的题型多刷刷。
12、现在推荐在工业界基本都用match+ranking的架构,但是学术界论文中的大多算法算是没有区分吗?end-to-end的方式,还是算是召回?
学术界论文往往不针对整个推荐系统,而只针对match或者ranking阶段的某一种方法进行研究。比如DeepFM、Wide & Deep,只针对ranking阶段。而阿里有几篇介绍embedding的论文,只介绍match阶段的方法。end-to-end的方式,在match和ranking阶段都有吧。