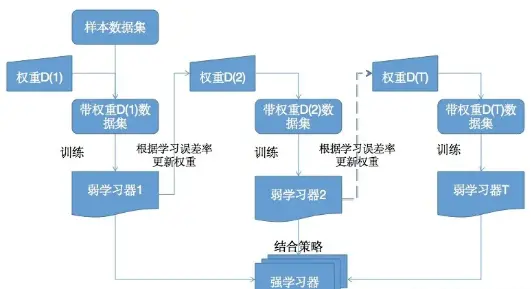
Boosting算法的工作机制
- 用初始权重D(1)从数据集中训练出一个弱学习器1
- 根据弱学习1的学习误差率表现来更新训练样本的权重D(2),使得之前弱学习器1学习误差率高的样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。
- 然后基于调整权重后的训练集来训练弱学习器2
- 如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
现如今已经有很多的提升方法了,但最著名的就是Adaboost(适应性提升,是Adaptive Boosting的简称)和Gradient Boosting(梯度提升)。让我们先从 Adaboost 说起。
什么是AdaBoost
AdaBoost是一个具有里程碑意义的算法,其中,适应性(adaptive)是指:后续的分类器为更好地支持被先前分类器分类错误的样本实例而进行调整。通过对之前分类结果不对的训练实例多加关注,使新的预测因子越来越多地聚焦于之前错误的情况。
具体说来,整个AdaBoost迭代算法就3步:
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
加法模型与前向分布
在学习AdaBoost之前需要了解两个数学问题,这两个数学问题可以帮助我们更好地理解AdaBoost算法,并且在面试官问你算法原理时不至于发懵。下面我们就来看看加法模型与前向分布。
什么是加法模型
当别人问你“什么是加法模型”时,你应当知道:加法模型顾名思义就是把各种东西加起来求和。如果想要更严谨的定义,不妨用数学公式来表达:
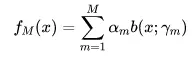
这个公式看上去可能有些糊涂,如果我们套用到提升树模型中就比较容易理解一些。FM(x)表示最终生成的最好的提升树,其中M表示累加的树的个数。b(x;ym)表示一个决策树,$阿尔法m$ 表示第m个决策树的权重,ym表示决策树的参数(如叶节点的个数)。
什么是前向分布
那么什么是前向分布算法呢?在损失函数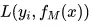 的条件下,加法模型FM(x)成为一个经验风险极小化问题,即使得损失函数极小化:
的条件下,加法模型FM(x)成为一个经验风险极小化问题,即使得损失函数极小化:
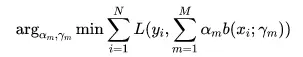
前向分布算法就是求解这个优化问题的一个思想:因为学习的是加法模型,如果能够从前向后,每一步只学习一个基函数(一棵决策树)及其权重,利用残差逐步逼近优化问题,那么就可以简化优化的复杂度。从而得到前向分布算法为:
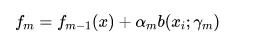
套用在提升树模型中进行理解就是:$fm-1(x)$是前一棵提升树(之前树的累加),在其基础上再加上一棵树$Bxi, Ym$乘上它的权重系数,用这棵树去拟合的残差!$阿尔法m$(观察值与估计值之间的差),再将这两棵树合在一起就得到了新的提升树。实际上就是让下一个基分类器去拟合当前分类器学习出来的残差。
前向分布与Adaboost损失函数优化的关系
现在了解了加法模型与前向分布。那这两个概念与Adaboost又有什么关系呢?
Adaboost可以认为其模型是加法模型、损失函数为指数函数、学习算法为前向分步算法的二类分类学习方法。我们可以使用前向分布算法作为框架,推导出Adaboost算法的损失函数优化问题的。
在Adaboost中,各个基本分类器就相当于加法模型中的基函数$fm-1(x)$,且其损失函数为指数函数$b(xi;ym)$。
即,需要优化的问题如下:
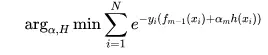
如果我们令,则上述公式可以改写成为:
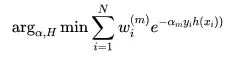
因为与要么相等、要么不等。所以可以将其拆成两部分相加的形式:

算法中需要关注的内容
首先看看算法中都关注了哪些内容: 首先,我们假设训练样本为$(x1,y1), (x2, y2)…(xn, yn)$
由于AdaBoost是由一个个的弱分类器迭代训练得到一个强分类器的,因此我们有如下定义:
- 弱分类器表达式:$Ht(x)$
先以二分类为例,它输出的值为1或-1,则有:$Ht(x) ∈{-1, 1}$
首先,我们假设训练样本为
由于AdaBoost是由一个个的弱分类器迭代训练得到一个强分类器的,因此我们有如下定义:
- 弱分类器表达式:

公式推导(通过Z最小化训练误差)
Adaboost算法之所以称为十大算法之一,有一个重要原因就是它有完美的数学推导过程,其参数不是人工设定的,而是有解析解的,并且可以证明其误差上界越来越小,趋近于零;且可以推导出来。下面就来看一下公式推导。
权重公式:
首先要把模型的误差表示出来,只有用数学公式表示出来,才能够讲模型的优化。
先看第i个样本在t+1个弱学习器的权重是怎样的?

模型误差上限

模型误差上限最小化与Z

求出Z
既然最小化Zt就等同于最小化模型误差上界,那我们得先知道Zt长什么样,然后才能去最小化它。
我们在前面已经说过,为了保证所有样本的权重加起来等于1。因此需要对每个权重除以归一化系数。即Zt实际上就是t+1时刻所有样本原始权重和,也就是时刻的各点权重乘以调整幅度再累加:

求出使得Z最小的参数a


AdaBoost计算步骤梳理及优缺点
 理论上任何学习器都可以用于Adaboost。但一般来说,使用最广泛的Adaboost弱学习器是决策树和神经网络。对于决策树,Adaboost分类用了CART分类树,而Adaboost回归用了CART回归树。
理论上任何学习器都可以用于Adaboost。但一般来说,使用最广泛的Adaboost弱学习器是决策树和神经网络。对于决策树,Adaboost分类用了CART分类树,而Adaboost回归用了CART回归树。