简介
在推荐、搜索、广告等领域,CTR(click-through rate)预估是一项非常核心的技术,这里引用阿里妈妈资深算法专家朱小强大佬的一句话:“它(CTR预估)是镶嵌在互联网技术上的明珠”。
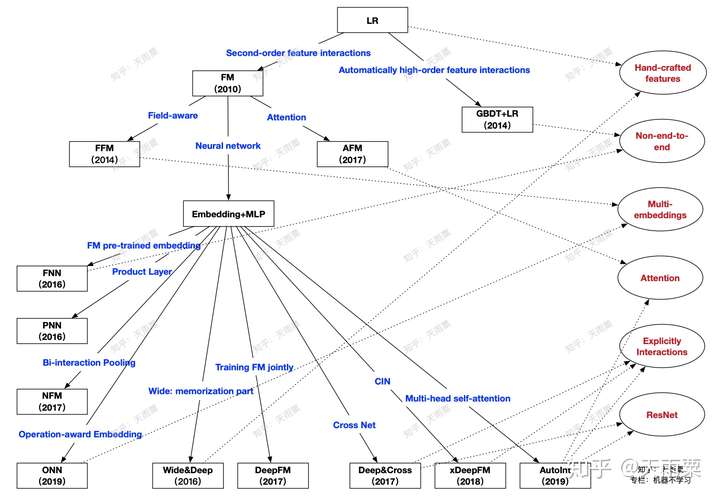
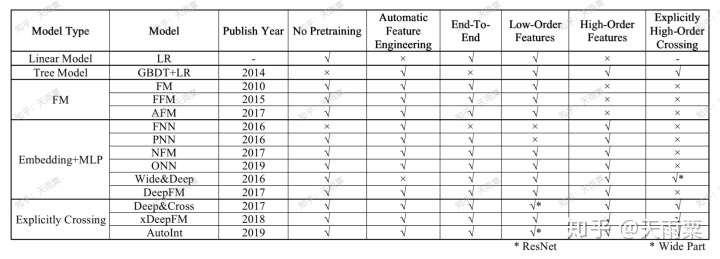
本篇文章主要是对CTR预估中的常见模型进行梳理与总结,并分成模块进行概述。每个模型都会从「模型结构」、「优势」、「不足」三个方面进行探讨,在最后对所有模型之间的关系进行比较与总结。本篇文章讨论的模型如下图所示(原创图),这个图中展示了本篇文章所要讲述的算法以及之间的关系,在文章的最后总结会对这张图进行详细地说明。
一. 分布式线性模型
Logistic Regression
Logistic Regression是每一位算法工程师再也熟悉不过的基本算法之一了,毫不夸张地说,LR作为最经典的统计学习算法几乎统治了早期工业机器学习时代。这是因为其具备简单、时间复杂度低、可大规模并行化等优良特性。在早期的CTR预估中,算法工程师们通过手动设计交叉特征以及特征离散化等方式,赋予LR这样的线性模型对数据集的非线性学习能力,高维离散特征+手动交叉特征构成了CTR预估的基础特征。LR在工程上易于大规模并行化训练恰恰适应了这个时代的要求。
模型结构:
优势:
- 模型简单,具备一定可解释性
- 计算时间复杂度低
- 工程上可大规模并行化
不足:
- 依赖于人工大量的特征工程,例如需要根据业务背知识通过特征工程融入模型
- 特征交叉难以穷尽
- 对于训练集中没有出现的交叉特征无法进行参数学习
二. 自动化特征工程
GBDT + LR(2014)—— 特征自动化时代的初探索
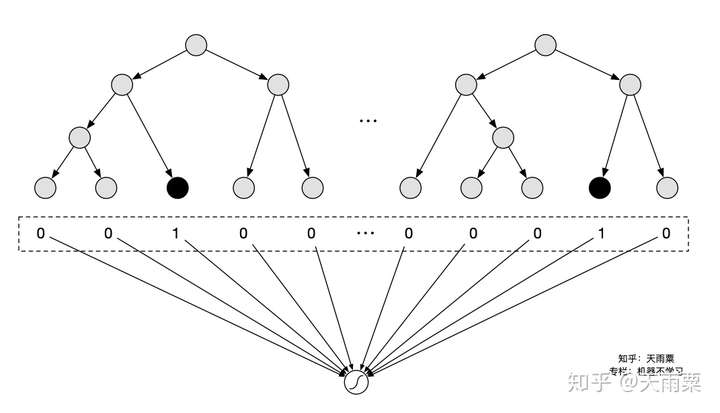
Facebook在2014年提出了GBDT+LR的组合模型来进行CTR预估,其本质上是通过Boosting Tree模型本身的特征组合能力来替代原先算法工程师们手动组合特征的过程。GBDT等这类Boosting Tree模型本身具备了特征筛选能力(每次分裂选取增益最大的分裂特征与分裂点)以及高阶特征组合能力(树模型天然优势)对应树的一条路径(用叶子节点来表示),因此通过GBDT来自动生成特征向量就成了一个非常自然的思路。注意这里虽然是两个模型的组合,但实际并非是端到端的模型,而是两阶段的、解耦的,即先通过GBDT训练得到特征向量后,再作为下游LR的输入,LR的在训练过程中并不会对GBDT进行更新。
模型结构:
通过GBDT训练模型,得到组合的特征向量。例如训练了两棵树,每棵树有5个叶子结点,对于某个特定样本来说,落在了第一棵树的第3个结点,此时我们可以得到向量
;落在第二棵树的第4个结点,此时的到向量
;那么最终通过concat所有树的向量,得到这个样本的最终向量
。将这个向量作为下游LR模型的inputs,进行训练。
优势:
- 特征工程自动化,通过Boosting Tree模型的天然优势自动探索特征组合
不足:
- 两阶段的、非端到端的模型
- CTR预估场景涉及到大量高维稀疏特征,树模型并不适合处理(因此实际上会将dense特征或者低维的离散特征给GBDT,剩余高维稀疏特征在LR阶段进行训练)
- GBDT模型本身比较复杂,无法做到online learning,模型对数据的感知相对较滞后(必须提高离线模型的更新频率)
由于LR善于处理离散特征,GBDT善于处理连续特征。所以也可以交由GBDT处理连续特征,输出结果拼接上离散特征一起输入LR。
三. FM模型以及变体
(1)FM:Factorization Machines, 2010 —— 隐向量学习提升模型表达
FM是在2010年提出的一种可以学习二阶特征交叉的模型,通过在原先线性模型的基础上,枚举了所有特征的二阶交叉信息后融入模型,提高了模型的表达能力。但不同的是,模型在二阶交叉信息的权重学习上,采用了隐向量内积(也可看做embedding)的方式进行学习。
FM和基于树的模型(e.g. GBDT)都能够自动学习特征交叉组合。基于树的模型适合连续中低度稀疏数据,容易学到高阶组合。但是树模型却不适合学习高度稀疏数据的特征组合,一方面高度稀疏数据的特征维度一般很高,这时基于树的模型学习效率很低,甚至不可行;另一方面树模型也不能学习到训练数据中很少或没有出现的特征组合。相反,FM模型因为通过隐向量的内积来提取特征组合,对于训练数据中很少或没有出现的特征组合也能够学习到。例如,特征
和特征
在训练数据中从来没有成对出现过,但特征
经常和特征
成对出现,特征
也经常和特征
成对出现,因而在FM模型中特征
和特征
也会有一定的相关性。毕竟所有包含特征
的训练样本都会导致模型更新特征
的隐向量
,同理,所有包含特征
的样本也会导致模型更新隐向量
,这样
就不太可能为0。
模型结构:
FM的公式包含了一阶线性部分与二阶特征交叉部分:
在LR中,一般是通过手动构造交叉特征后,喂给模型进行训练,例如我们构造性别与广告类别的交叉特征:
(gender=’女’ & ad_category=’美妆’),此时我们会针对这个交叉特征学习一个参数
。但是在LR中,参数梯度更新公式与该特征取值
关系密切:
,当
取值为0时,参数
就无法得到更新,而
要非零就要求交叉特征的两项都要非零,但实际在数据高度稀疏,一旦两个特征只要有一个取0,参数
不能得到有效更新;除此之外,对于训练集中没有出现的交叉特征,也没办法学习这类权重,泛化性能不够好。
另外,在FM中通过将特征隐射到k维空间求内积的方式,打破了交叉特征权重间的隔离性(break the independence of the interaction parameters),增加模型在稀疏场景下学习交叉特征的能力。一个交叉特征参数的估计,可以帮助估计其他相关的交叉特征参数。例如,假设我们有交叉特征gender=male & movie_genre=war,我们需要估计这个交叉特征前的参数
,FM通过将
分解为
的方式进行估计,那么对于每次更新male或者war的隐向量
时,都会影响其他与male或者war交叉的特征参数估计,使得特征权重的学习不再互相独立。这样做的好处是,对于traindata set中没有出现过的交叉特征,FM仍然可以给到一个较好的非零预估值。
优势:
- 可以有效处理稀疏场景下的特征学习
- 具有线性时间复杂度(化简思路:
)
- 对训练集中未出现的交叉特征信息也可进行泛化
不足:
- 2-way的FM仅枚举了所有特征的二阶交叉信息,没有考虑高阶特征的信息
FFM(Field-aware Factorization Machine)是Yuchin Juan等人在2015年的比赛中提出的一种对FM改进算法,主要是引入了field概念,即认为每个feature对于不同field的交叉都有不同的特征表达。FFM相比于FM的计算时间复杂度更高,但同时也提高了本身模型的表达能力。FM也可以看成只有一个field的FFM,这里不做过多赘述。
(2)AFM:Attentional Factorization Machines, 2017 —— 引入Attention机制的FM
AFM全称Attentional Factorization Machines,顾名思义就是引入Attention机制的FM模型。我们知道FM模型枚举了所有的二阶交叉特征(second-order interactions),即
,实际上有一些交叉特征可能与我们的预估目标关联性不是很大;AFM就是通过Attention机制来学习不同二阶交叉特征的重要性(这个思路与FFM中不同field特征交叉使用不同的embedding实际上是一致的,都是通过引入额外信息来表达不同特征交叉的重要性)。
举例来说,在预估用户是否会点击广告时,我们假设有用户性别、广告版位尺寸大小、广告类型三个特征,分别对应三个embedding:
,
,
,对于用户“是否点击”这一目标
来说,显然性别与ad_size的交叉特征对于
的相关度不大,但性别与ad_category的交叉特征(如gender=女性&category=美妆)就会与
更加相关;换句话说,我们认为当性别与ad_category交叉时,重要性应该要高于性别与ad_size的交叉;FFM中通过引入Field-aware的概念来量化这种与不同特征交叉时的重要性,AFM则是通过加入Attention机制,赋予重要交叉特征更高的重要性。
模型结构:
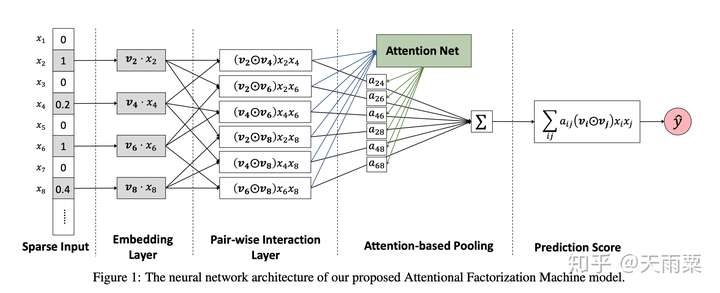
AFM在FM的二阶交叉特征上引入Attention权重,公式如下:
其中
代表element-wise的向量相乘,下同。
其中,
是模型所学习到的
与
特征交叉的重要性,其公式如下:
我们可以看到这里的权重
实际是通过输入
和
训练了一个一层隐藏层的NN网络,让模型自行去学习这个权重。
对比AFM和FM的公式我们可以发现,AFM实际上是FM的更加泛化的一种形式。当我们令向量
,权重
时,AFM就会退化成FM模型。
优势:
- 在FM的二阶交叉项上引入Attention机制,赋予不同交叉特征不同的重要度,增加了模型的表达能力
- Attention的引入,一定程度上增加了模型的可解释性
不足:
- 仍然是一种浅层模型,模型没有学习到高阶的交叉特征
四. Embedding+MLP结构下的浅层改造
本章所介绍的都是具备Embedding+MLP这样结构的模型,之所以称作浅层改造,主要原因在于这些模型都是在embedding层进行的一些改变,例如FNN的预训练Embedding、PNN的Product layer、NFM的Bi-Interaction Layer等等,这些改变背后的思路可以归纳为:使用复杂的操作让模型在浅层尽可能包含更多的信息,降低后续下游MLP的学习负担。
(1)FNN: Factorisation Machine supported Neural Network, 2016 —— 预训练Embedding的NN模型
FNN是2016年提出的一种基于FM预训练Embedding的NN模型,其思路也比较简单;FM本身具备学习特征Embedding的能力,DNN具备高阶特征交叉的能力,因此将两者结合是很直接的思路。FM预训练的Embedding可以看做是“先验专家知识”,直接将专家知识输入NN来进行学习。注意,FNN本质上也是两阶段的模型,与Facebook在2014年提出GBDT+LR模型在思想上一脉相承。
模型结构:
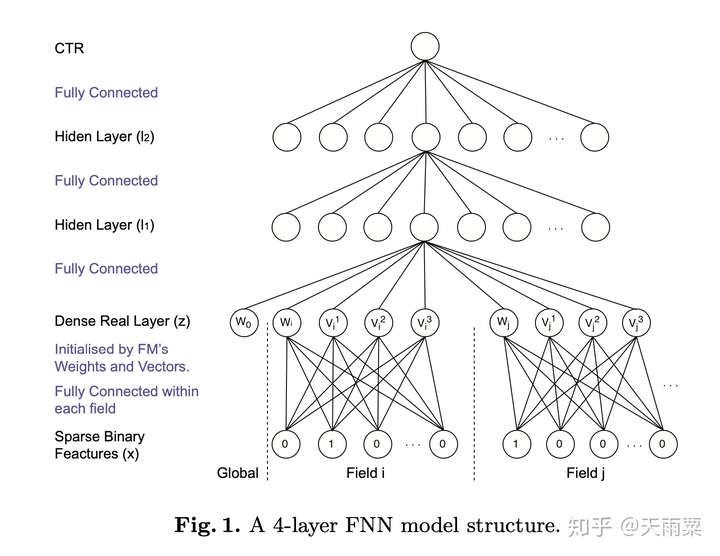
FNN本身在结构上并不复杂,如上图所示,就是将FM预训练好的Embedding向量直接喂给下游的DNN模型,让DNN来进行更高阶交叉信息的学习。
优势:
- 离线训练FM得到embedding,再输入NN,相当于引入先验专家经验
- 加速模型的训练和收敛
- NN模型省去了学习feature embedding的步骤,训练开销低
不足:
- 非端到端的两阶段模型,不利于online learning
- 预训练的Embedding受到FM模型的限制
- FNN中只考虑了特征的高阶交叉,并没有保留低阶特征信息
(2)PNN:Product-based Neural Network, 2016 —— 引入不同Product操作的Embedding层
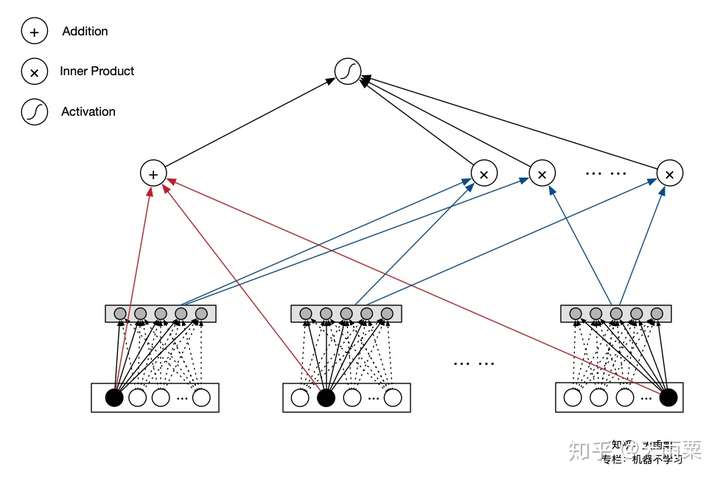
PNN是2016年提出的一种在NN中引入Product Layer的模型,其本质上和FNN类似,都属于Embedding+MLP结构。作者认为,在DNN中特征Embedding通过简单的concat或者add都不足以学习到特征之间复杂的依赖信息,因此PNN通过引入Product Layer来进行更复杂和充分的特征交叉关系的学习。PNN主要包含了IPNN和OPNN两种结构,分别对应特征之间Inner Product的交叉计算和Outer Product的交叉计算方式。
模型结构:
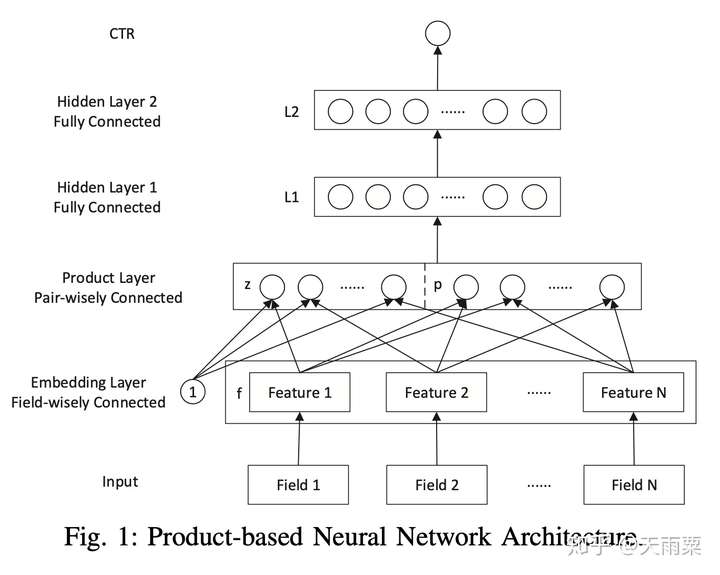
PNN结构显示通过Embedding Lookup得到每个field的Embedding向量,接着将这些向量输入Product Layer,在Product Layer中包含了两部分,一部分是左边的
,就是将特征原始的Embedding向量直接保留;另一部分是右侧的
,即对应特征之间的product操作;可以看到PNN相比于FNN一个优势就是保留了原始的低阶embedding特征。
在PNN中,由于引入Product操作,会使模型的时间和空间复杂度都进一步增加。这里以IPNN为例,其中
是pair-wise的特征交叉向量,假设我们共有N个特征,每个特征的embedding信息
;在Inner Product的情况下,通过交叉项公式
会得到
(其中
是对称矩阵),此时从Product层到
层(假设
层有
个结点),对于
层的每个结点我们有:
,因此这里从product layer到L1层参数空间复杂度为
;作者借鉴了FM的思想对参数
进行了矩阵分解:
,此时L1层每个结点的计算可以化简为:
,空间复杂度退化
。
优势:
- PNN通过
保留了低阶Embedding特征信息
- 通过Product Layer引入更复杂的特征交叉方式,
不足:
- 计算时间复杂度相对较高
(3)NFM:Neural Factorization Machines, 2017 —— 引入Bi-Interaction Pooling结构的NN模型
NFM全程为Neural Factorization Machines,它与FNN一样,都属于将FM与NN进行结合的模型。但不同的是NFM相比于FNN是一种端到端的模型。NFM与PNN也有很多相似之出,本质上也属于Embedding+MLP结构,只是在浅层的特征交互上采用了不同的结构。NFM将PNN的Product Layer替换成了Bi-interaction Pooling结构来进行特征交叉的学习。
模型结构:
NFM的整个模型公式为:
其中
是Bi-Interaction Pooling+NN部分的输出结果。我们重点关注NFM中的Bi-Interaction Pooling层:
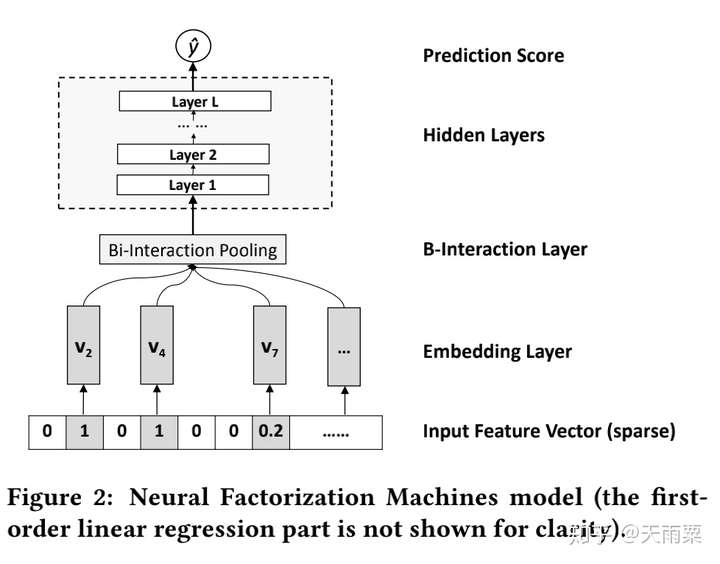
NFM的结构如上图所示,通过对特征Embedding之后,进入Bi-Interaction Pooling层。这里注意一个小细节,NFM的对Dense Feature,Embedding方式于AFM相同,将Dense Feature Embedding以后再用dense feature原始的数据进行了scale,即
。
NFM的Bi-Interaction Pooling层是对两两特征的embedding进行element-wise的乘法,公式如下:
假设我们每个特征Embedding向量的维度为
,则
,Bi-Interaction Pooling的操作简单来说就是将所有二阶交叉的结果向量进行sum pooling后再送入NN进行训练。对比AFM的Attention层,Bi-Interaction Pooling层采用直接sum的方式,缺少了Attention机制;对比FM莫明星,NFM如果将后续DNN隐藏层删掉,就会退化为一个FM模型。
NFM在输入层以及Bi-Interaction Pooling层后都引入了BN层,也加速了模型了收敛。
优势:
- 相比于Embedding的concat操作,NFM在low level进行interaction可以提高模型的表达能力
- 具备一定高阶特征交叉的能力
- Bi-Interaction Pooling的交叉具备线性计算时间复杂度
不足:
- 直接进行sum pooling操作会损失一定的信息,可以参考AFM引入Attention
(4)ONN:Operation-aware Neural Network, 2019 —— FFM与NN的结合体
ONN是2019年发表的CTR预估,我们知道PNN通过引入不同的Product操作来进行特征交叉,ONN认为针对不同的特征交叉操作,应该用不同的Embedding,如果用同样的Embedding,那么各个不同操作之间就会互相影响而最终限制了模型的表达。
我们会发现ONN的思路在本质上其实和FFM、AFM都有异曲同工之妙,这三个模型都是通过引入了额外的信息来区分不同field之间的交叉应该具备不同的信息表达。总结下来:
- FFM:引入Field-aware,对于field a来说,与field b交叉和field c交叉应该用不同的embedding
- AFM:引入Attention机制,a与b的交叉特征重要度与a与c的交叉重要度不同
- ONN:引入Operation-aware,a与b进行内积所用的embedding,不同于a与b进行外积用的embedding
对比上面三个模型,本质上都是给模型增加更多的表达能力,个人觉得ONN就是FFM与NN的结合。
模型结构:
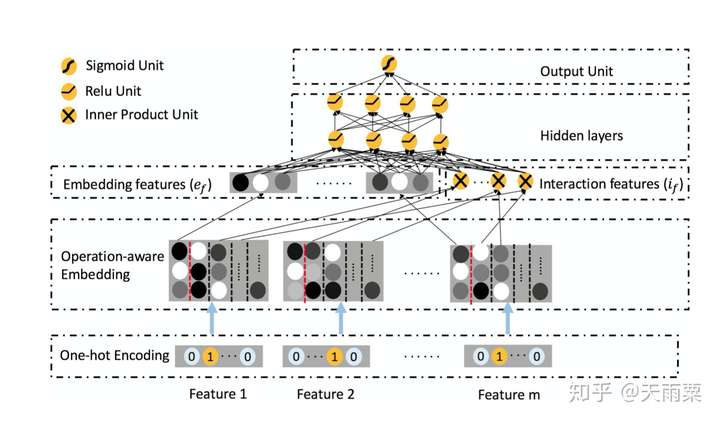
ONN沿袭了Embedding+MLP结构。在Embedding层采用Operation-aware Embedding,可以看到对于一个feature,会得到多个embedding结果;在图中以红色虚线为分割,第一列的embedding是feature本身的embedding信息,从第二列开始往后是当前特征与第n个特征交叉所使用的embedding。
在Embedding features层中,我们可以看到包含了两部分:
- 左侧部分为每个特征本身的embedding信息,其代表了一阶特征信息
- 右侧部分是与FFM相同的二阶交叉特征部分
这两部分concat之后接入MLP得到最后的预测结果。
优势:
- 引入Operation-aware,进一步增加了模型的表达能力
- 同时包含了特征一阶信息与高阶交叉信息
不足:
- 模型复杂度相对较高,每个feature对应多个embedding结果
五. 双路并行的模型组合
这一部分将介绍双路并行的模型结构,之所以称为双路并行,是因为在这一部分的模型中,以Wide&Deep和DeepFM为代表的模型架构都是采用了双路的结构。例如Wide&Deep的左路为Embedding+MLP,右路为Cross Feature LR;DeepFM的左路为FM,右路为Embedding+MLP。这类模型通过使用不同的模型进行联合训练,不同子模型之间互相弥补,增加整个模型信息表达和学习的多样性。
(1)WDL:Wide and Deep Learning, 2016 —— Memorization与Generalization的信息互补
Wide And Deep是2016年Google提出的用于Google Play app推荐业务的一种算法。其核心思想是通过结合Wide线性模型的记忆性(memorization)和Deep深度模型的泛化性(generalization)来对用户行为信息进行学习建模。
模型结构:
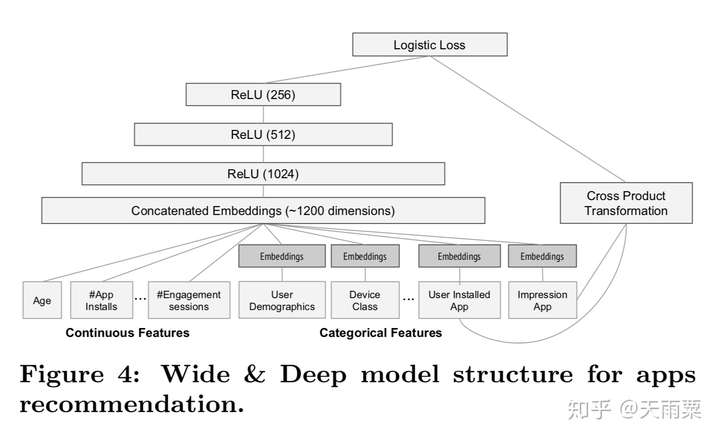
优势:
- Wide层与Deep层互补互利,Deep层弥补Memorization层泛化性不足的问题
- wide和deep的joint training可以减小wide部分的model size(即只需要少数的交叉特征)
- 可以同时学习低阶特征交叉(wide部分)和高阶特征交叉(deep部分)
不足:
- 仍需要手动设计交叉特征
(2)DeepFM:Deep Factorization Machines, 2017 —— FM基础上引入NN隐式高阶交叉信息
我们知道FM只能够去显式地捕捉二阶交叉信息,而对于高阶的特征组合却无能为力。DeepFM就是在FM模型的基础上,增加DNN部分,进而提高模型对于高阶组合特征的信息提取。DeepFM能够做到端到端的、自动的进行高阶特征组合,并且不需要人工干预。
模型结构:
DeepFM包含了FM和NN两部分,这两部分共享了Embedding层:
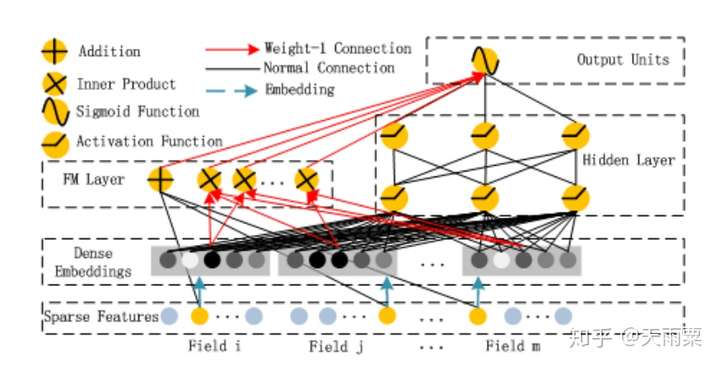
左侧FM部分就是2-way的FM:包含了线性部分和二阶交叉部分右侧NN部分与FM共享Embedding,将所有特征的embedding进行concat之后作为NN部分的输入,最终通过NN得到。
优势:
- 模型具备同时学习低阶与高阶特征的能力
- 共享embedding层,共享了特征的信息表达
不足:
- DNN部分对于高阶特征的学习仍然是隐式的
参考: