概述
GBDT的加入,是为了弥补LR难以实现特征组合的缺点。
LR
LR作为一个线性模型,以概率形式输出结果,在工业上得到了十分广泛的应用。 其具有简单快速高效,结果可解释,可以分布式计算。搭配L1,L2正则,可以有很好地鲁棒性以及挑选特征的能力。
但由于其简单,也伴随着拟合能力不足,无法做特征组合的缺点。
通过梯度下降法可以优化参数
可以称之上是 CTR 预估模型的开山鼻祖,也是工业界使用最为广泛的 CTR 预估模型
但是在CTR领域,单纯的LR虽然可以快速处理海量高维离散特征,但是由于线性模型的局限性,其在特征组合方面仍有不足,所以后续才发展出了FM来引入特征交叉。在此之前,业界也有使用GBDT来作为特征组合的工具,其结果输出给LR。
LR 优缺点
优点:由于 LR 模型简单,训练时便于并行化,在预测时只需要对特征进行线性加权,所以性能比较好,往往适合处理海量 id 类特征,用 id 类特征有一个很重要的好处,就是防止信息损失(相对于范化的 CTR 特征),对于头部资源会有更细致的描述。
缺点:LR 的缺点也很明显,首先对连续特征的处理需要先进行离散化,如上文所说,人工分桶的方式会引入多种问题。另外 LR 需要进行人工特征组合,这就需要开发者有非常丰富的领域经验,才能不走弯路。这样的模型迁移起来比较困难,换一个领域又需要重新进行大量的特征工程。
GBDT+LR
首先,GBDT是一堆树的组合,假设有k棵树
。
对于第i棵树
,其存在
个叶子节点。而从根节点到叶子节点,可以认为是一条路径,这条路径是一些特征的组合,例如从根节点到某一个叶子节点的路径可能是“
”这就是一组特征组合。到达这个叶子节点的样本都拥有这样的组合特征,而这个组合特征使得这个样本得到了GBDT的预测结果。
所以对于GBDT子树
,会返回一个
维的one-hot向量
对于整个GBDT,会返回一个
维的向量
,这个向量由0-1组成。
然后,这个
,会作为输入,送进LR模型,最终输出结果
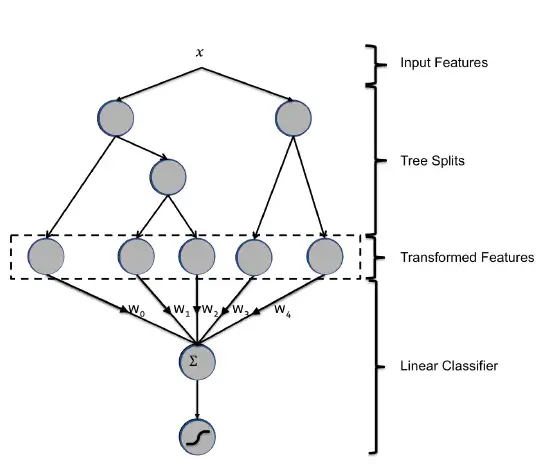
模型大致如图所示。上图中由两棵子树,分别有3和2个叶子节点。对于一个样本x,最终可以落入第一棵树的某一个叶子和第二棵树的某一个叶子,得到两个独热编码的结果例如 [0,0,1],[1,0]组合得[0,0,1,1,0]输入到LR模型最后输出结果。
由于LR善于处理离散特征,GBDT善于处理连续特征。所以也可以交由GBDT处理连续特征,输出结果拼接上离散特征一起输入LR。
讨论
至于GBDT为何不善于处理高维离散特征?
https://cloud.tencent.com/developer/article/1005416
缺点:对于海量的 id 类特征,GBDT 由于树的深度和棵树限制(防止过拟合),不能有效的存储;另外海量特征在也会存在性能瓶颈,经笔者测试,当 GBDT 的 one hot 特征大于 10 万维时,就必须做分布式的训练才能保证不爆内存。所以 GBDT 通常配合少量的反馈 CTR 特征来表达,这样虽然具有一定的范化能力,但是同时会有信息损失,对于头部资源不能有效的表达。
https://www.zhihu.com/question/35821566
后来思考后发现原因是因为现在的模型普遍都会带着正则项,而 lr 等线性模型的正则项是对权重的惩罚,也就是 W1一旦过大,惩罚就会很大,进一步压缩 W1的值,使他不至于过大,而树模型则不一样,树模型的惩罚项通常为叶子节点数和深度等,而我们都知道,对于上面这种 case,树只需要一个节点就可以完美分割9990和10个样本,惩罚项极其之小. 这也就是为什么在高维稀疏特征的时候,线性模型会比非线性模型好的原因了:带正则化的线性模型比较不容易对稀疏特征过拟合。
GBDT当树深度>2时,其实组合的是多元特征了,而且由于子树规模的限制,导致其特征组合的能力并不是很强,所以才有了后续FM,FFM的发展x
GBDT + LR 改进
Facebook 的方案在实际使用中,发现并不可行,因为广告系统往往存在上亿维的 id 类特征(用户 guid10 亿维,广告 aid 上百万维),而 GBDT 由于树的深度和棵树的限制,无法存储这么多 id 类特征,导致信息的损失。有如下改进方案供读者参考:
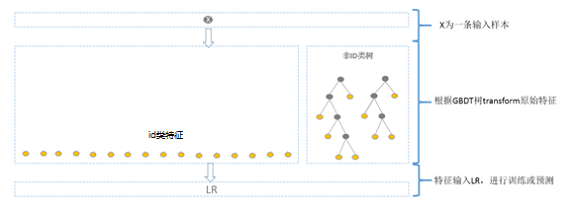
**方案一:**GBDT 训练除 id 类特征以外的所有特征,其他 id 类特征在 LR 阶段再加入。这样的好处很明显,既利用了 GBDT 对连续特征的自动离散化和特征组合,同时 LR 又有效利用了 id 类离散特征,防止信息损失。
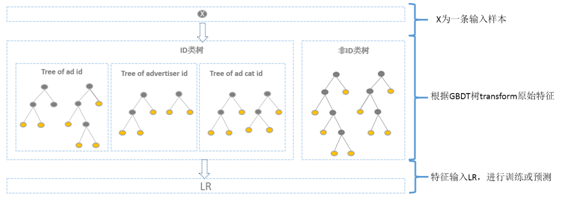
**方案二:**GBDT 分别训练 id 类树和非 id 类树,并把组合特征传入 LR 进行二次训练。对于 id 类树可以有效保留头部资源的信息不受损失;对于非 id 类树,长尾资源可以利用其范化信息(反馈 CTR 等)。但这样做有一个缺点是,介于头部资源和长尾资源中间的一部分资源,其有效信息即包含在范化信息(反馈 CTR) 中,又包含在 id 类特征中,而 GBDT 的非 id 类树只存的下头部的资源信息,所以还是会有部分信息损失。
优缺点:
优点:GBDT 可以自动进行特征组合和离散化,LR 可以有效利用海量 id 类离散特征,保持信息的完整性。
缺点:LR 预测的时候需要等待 GBDT 的输出,一方面 GBDT在线预测慢于单 LR,另一方面 GBDT 目前不支持在线算法,只能以离线方式进行更新。