一、概述
网络表示学习(Representation Learning on Network),一般说的就是向量化(Embedding)技术,简单来说,就是将网络中的结构(节点、边或者子图),通过一系列过程,变成一个多维向量,通过这样一层转化,能够将复杂的网络信息变成结构化的多维特征,从而利用机器学习方法实现更方便的算法应用
主流的KG embedding的方法包括基于平移的模型(典型代表:TransE),基于矩阵分解的模型(典型代表:RESCAL),基于神经网络的模型(典型代表:NTN)和基于图神经网络的模型(典型代表:RGCN)。
我们开始介绍知识表示学习的几个代表模型,包括:结构向量模型、语义匹配能量模型、隐变量模型、神经张量网络模型、矩阵分解模型和平移模型,等等。
但是传统的KG embedding模型存在一些不足,例如大多数方法完全依赖于知识图谱中的三元组数据,知识图谱表示学习过程缺乏可解释性。针对完全依赖于三元组数据的问题,一类有效的方案是引入知识图谱图结构中存在的路径信息,经典的基于路径的KG embedding的方法是PTransE,对于由关系路径中的所有关系的向量表示,PTtransE通过求和、乘积和RNN三种策略进行路径的组合。然而,现有的基于路径的知识图谱表示学习模型的路径表示过程中完全基于数据驱动,缺乏可解释性。同时,PTransE,PathRNN等完全数据驱动的方法在表示路径的过程中会造成误差累积并进一步限制路径表示的精度。
目前提到图算法一般指:
经典数据结构与算法层面的:最小生成树(Prim,Kruskal,…),最短路(Dijkstra,Floyed,…),拓扑排序,关键路径等
概率图模型,涉及图的表示,推断和学习,详细可以参考Koller的书或者公开课
图神经网络,主要包括Graph Embedding(基于随机游走)和Graph CNN(基于邻居汇聚)两部分。
二、Trans 系列
现在主要介绍知识表示学习的一个最简单也是最有效的方案,叫TransE。在这个模型中,每个实体和关系都表示成低维向量。那么如何怎么学习这些低维向量呢?我们需要设计一个学习目标,这个目标就是,给定任何一个三元组,我们都将中间的relation看成是从head到tail的一个翻译过程,也就是说把head的向量加上relation的向量,要让它尽可能地等于tail向量。在学习过程中,通过不断调整、更新实体和关系向量的取值,使这些等式尽可能实现。
些实体和关系的表示可以用来做什么呢?一个直观的应用就是Entity Prediction(实体预测)。就是说,如果给一个head entity,再给一个relation,那么可以利用刚才学到的向量表示,去预测它的tail entity可能是什么。思想非常简单,直接把h r,然后去找跟h r向量最相近的tail向量就可以了。实际上,我们也用这个任务来判断不同表示模型的效果。我们可以看到,以TransE为代表的翻译模型,需要学习的参数数量要小很多,但同时能够达到非常好的预测准确率。
trans 系列详解: http://aiblog.top/2019/07/08/Trans%E7%B3%BB%E5%88%97%E6%A8%A1%E5%9E%8B%E8%AF%A6%E8%A7%A3/
这里举一些例子。首先,利用TransE学到的实体表示,我们可以很容易地计算出跟某个实体最相似的实体。大家可以看到
,关于中国、奥巴马、苹果,通过TransE向量得到的相似实体能够非常好地反映这些实体的关联。
如果已知head entity和relation,我们可以用TransE模型判断对应的tail entity是什么。比如说与中国相邻的国家或者地区,可以看到比较靠前的实体均比较相关。比如说奥巴马曾经入学的学校,虽然前面的有些并不准确,但是基本上也都是大学或教育机构。
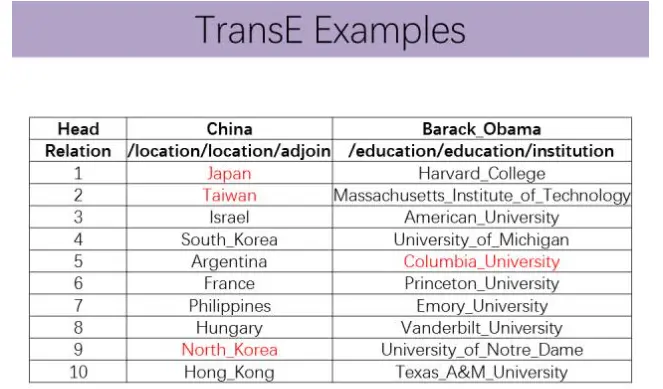
很多情况下TransE关于h r=t的假设其实本身并不符合实际。为什么呢?假如头实体是美国,关系是总统,而美国总统其实有非常多,我们拿出任意两个实体来,比如奥巴马和布什,这两个人都可以跟USA构成同样的关系。在这种情况下,对这两个三元组学习TransE模型,就会发现,它倾向于让奥巴马和布什在空间中变得非常接近。而这其实不太符合常理,因为奥巴马和布什虽然都是美国总统,但是在其他方面有千差万别。这其实就是涉及到复杂关系的处理问题,即所谓的1对N,N对1、N对N这些关系。刚才例子就是典型的1对N关系,就是一个USA可能会对应多个tail entity。为了解决TransE在处理复杂关系时的不足,研究者提出很多扩展模型,基本思想是,首先把实体按照关系进行映射,然后与该关系构建翻译等式。
1 - 1 transE 效果很好,但是1-N, N-1, N-N 这些复杂情况比较难。
TransH和TransR均为代表扩展模型之一,其中TransH由MSRA研究者提出,TransR由我们实验室提出。可以看到,TransE在实体预测任务能够达到47.1的准确率,而采用TransH和TransR,特别是TransR可以达到20%的提升。对于知识图谱复杂关系的处理,还有很多工作需要做。这里只是简介了一些初步尝试。
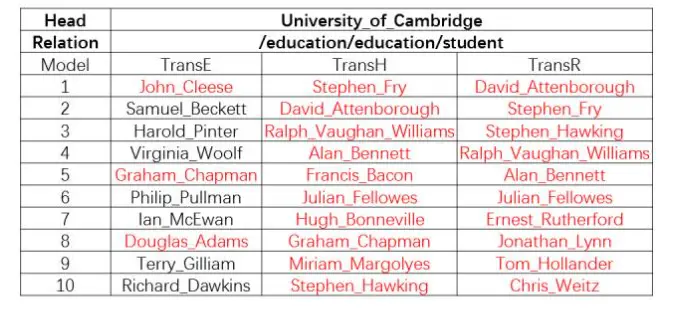
对于TransH和TransR的效果我们给出一些例子。比如对于《泰坦尼克号》电影,想看它的电影风格是什么,TransE得到的效果比TransH和TransR都要差一些。再如剑桥大学的杰出校友有哪些?我们可以看到对这种典型的1对N关系,TransR和TransH均做得更好一些。
Trans 系列Github: https://github.com/thunlp/OpenKE
考虑知识图谱复杂关系: 按照知识图谱中关系两端连接实体的对应数目,我们可以将关系划分为一对一、一对多、多对一和多对多四种类型。类型关系指的是,该类型关系中的一个左侧实体会平均对应多个右侧实体。 现有知识表示学习算法在处理四种类型关系时的性能差异较大。针对这个问题,我们提出了基于空间转移的 TransR 模型对不同的知识/关系的结构类型进行精细建模。
考虑知识图谱复杂路径: 在知识图谱中,有些多步关系路径也能够反映实体之间的关系。为了突破现有知识表示学习模型孤立学习每个三元组的局限性,我们将借鉴循环神经网络(Recursive Neural Networks)的学术思想,提出考虑关系路径的表示学习方法。我们以平移模型 TransE 作为基础进行扩展,提出 Path-based TransE(PTransE)模型对知识图谱中的复杂关系路径进行建模。
考虑知识图谱复杂属性: 现有知识表示学习模型将所有关系都表示为向量,这在极大程度上限制了对关系的语义的表示能力。这种局限性在属性知识的表示上尤为突出。我们面向属性知识,研究利用分类模型表示属性关系,通 过学习分类器建立实体与属性之间的关系,在既有知识图谱关系表示方案的基础上,探索具有更强表示能力的表示方案。
二、DeepWalk
DeepWalk的思想类似word2vec,使用图中节点与节点的共现关系来学习节点的向量表示。那么关键的问题就是如何来描述节点与节点的共现关系,DeepWalk给出的方法是使用随机游走(RandomWalk)的方式在图中进行节点采样。
RandomWalk是一种可重复访问已访问节点的深度优先遍历算法。给定当前访问起始节点,从其邻居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件。
获取足够数量的节点访问序列后,使用skip-gram model 进行向量学习。
DeepWalk 核心代码
DeepWalk算法主要包括两个步骤,第一步为随机游走采样节点序列,第二步为使用skip-gram modelword2vec学习表达向量。
①构建同构网络,从网络中的每个节点开始分别进行Random Walk 采样,得到局部相关联的训练数据;
②对采样数据进行SkipGram训练,将离散的网络节点表示成向量化,最大化节点共现,使用Hierarchical Softmax来做超大规模分类的分类器
Random Walk
我们可以通过并行的方式加速路径采样,在采用多进程进行加速时,相比于开一个进程池让每次外层循环启动一个进程,我们采用固定为每个进程分配指定数量的num_walks的方式,这样可以最大限度减少进程频繁创建与销毁的时间开销。
deepwalk_walk方法对应上一节伪代码中第6行,_simulate_walks对应伪代码中第3行开始的外层循环。最后的Parallel为多进程并行时的任务分配操作。
| |
Word2vec
这里就偷个懒直接用gensim里的Word2Vec了。
| |
DeepWalk应用
这里简单的用DeepWalk算法在wiki数据集上进行节点分类任务和可视化任务。 wiki数据集包含 2,405 个网页和17,981条网页之间的链接关系,以及每个网页的所属类别。
本例中的训练,评测和可视化的完整代码在下面的git仓库中,后面还会陆续更新line,node2vec,sdne,struc2vec等graph embedding算法以及一些GCN算法
| |
分类任务结果
micro-F1 : 0.6674
macro-F1 : 0.5768