概念
L0:计算非零个数,用于产生稀疏性,但是在实际研究中很少用,因为L0范数很难优化求解,是一个NP-hard问题,因此更多情况下我们是使用L1范数 L1:计算绝对值之和,用以产生稀疏性,因为它是L0范式的一个最优凸近似,容易优化求解 L2:计算平方和再开根号,L2范数更多是防止过拟合,并且让优化求解变得稳定很快速(这是因为加入了L2范式之后,满足了强凸)。
L1范数(Lasso Regularization):向量中各个元素绝对值的和。
L2范数(Ridge Regression):向量中各元素平方和再求平方根。
作用
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
L1正则化是在代价函数后面加上 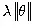
L2正则化是在代价函数后面增加了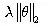
两者都起到一定的过拟合作用,两者都对应一定的先验知识,L1对应拉普拉斯分布,L2对应高斯分布,L1偏向于参数稀疏性,L2偏向于参数分布较为稠。