Word2vec 介绍
Word2Vec是google在2013年推出的一个NLP工具,它的特点是能够将单词转化为向量来表示。首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练;其次,该工具得到的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。随着深度学习(Deep Learning)在自然语言处理中应用的普及,很多人误以为word2vec是一种深度学习算法。其实word2vec算法的背后是一个浅层神经网络(有一个隐含层的神经元网络)。另外需要强调的一点是,word2vec是一个计算word vector的开源工具。当我们在说word2vec算法或模型的时候,其实指的是其背后用于计算word vector的CBOW模型和Skip-gram模型。很多人以为word2vec指的是一个算法或模型,这也是一种谬误。
用词向量来表示词并不是Word2Vec的首创,在很久之前就出现了。最早的词向量采用One-Hot编码,又称为一位有效编码,每个词向量维度大小为整个词汇表的大小,对于每个具体的词汇表中的词,将对应的位置置为1。转化为N维向量。
采用One-Hot编码方式来表示词向量非常简单,但缺点也是显而易见的,一方面我们实际使用的词汇表很大,经常是百万级以上,这么高维的数据处理起来会消耗大量的计算资源与时间。另一方面,One-Hot编码中所有词向量之间彼此正交,没有体现词与词之间的相似关系。
Word2vec 是 Word Embedding 方式之一,属于 NLP 领域。他是将词转化为「可计算」「结构化」的向量的过程。本文将讲解 Word2vec 的原理和优缺点。
什么是 Word2vec ?
什么是 Word Embedding ?
在说明 Word2vec 之前,需要先解释一下 Word Embedding。 它就是将「不可计算」「非结构化」的词转化为「可计算」「结构化」的向量。
这一步解决的是”将现实问题转化为数学问题“,是人工智能非常关键的一步。

将现实问题转化为数学问题只是第一步,后面还需要求解这个数学问题。所以 Word Embedding 的模型本身并不重要,重要的是生成出来的结果——词向量。因为在后续的任务中会直接用到这个词向量。
什么是 Word2vec ?
Word2vec 是 Word Embedding 的方法之一。他是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。
Word2vec 在整个 NLP 里的位置可以用下图表示:

Word2vec 的 2 种训练模式
CBOW(Continuous Bag-of-Words Model)和Skip-gram (Continuous Skip-gram Model),是Word2vec 的两种训练模式。CBOW适合于数据集较小的情况,而Skip-Gram在大型语料中表现更好。下面简单做一下解释:
词向量训练的预处理步骤:
1. 对输入的文本生成一个词汇表,每个词统计词频,按照词频从高到低排序,取最频繁的V个词,构成一个词汇表。每个词存在一个one-hot向量,向量的维度是V,如果该词在词汇表中出现过,则向量中词汇表中对应的位置为1,其他位置全为0。如果词汇表中不出现,则向量为全0
2. 将输入文本的每个词都生成一个one-hot向量,此处注意保留每个词的原始位置,因为是上下文相关的
3. 确定词向量的维数N
CBOW
通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么。

CBOW的处理步骤:
- 确定窗口大小window,对每个词生成2*window个训练样本,(i-window, i),(i-window+1, i),…,(i+window-1, i),(i+window, i)
- 确定batch_size,注意batch_size的大小必须是2*window的整数倍,这确保每个batch包含了一个词汇对应的所有样本
- 训练算法有两种:层次 Softmax 和 Negative Sampling 神经网络迭代训练一定次数,得到输入层到隐藏层的参数矩阵,矩阵中每一行的转置即是对应词的词向量
Skip-gram
用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词。

Skip-gram处理步骤:
- 确定窗口大小window,对每个词生成2*window个训练样本,(i, i-window),(i, i-window+1),…,(i, i+window-1),(i, i+window)
- 确定batch_size,注意batch_size的大小必须是2*window的整数倍,这确保每个batch包含了一个词汇对应的所有样本
- 训练算法有两种:层次 Softmax 和 Negative Sampling 神经网络迭代训练一定次数,得到输入层到隐藏层的参数矩阵,矩阵中每一行的转置即是对应词的词向量
我们先来看个最简单的例子。上面说到, y 是 x 的上下文,所以 y 只取上下文里一个词语的时候,语言模型就变成:
用当前词 x 预测它的下一个词 y
但如上面所说,一般的数学模型只接受数值型输入,这里的 x 该怎么表示呢? 显然不能用 Word2vec,因为这是我们训练完模型的产物,现在我们想要的是 x 的一个原始输入形式。
答案是:one-hot encoder
所谓 one-hot encoder,其思想跟特征工程里处理类别变量的 one-hot 一样。本质上是用一个只含一个 1、其他都是 0 的向量来唯一表示词语。
我举个例子,假设全世界所有的词语总共有 V 个,这 V 个词语有自己的先后顺序,假设『吴彦祖』这个词是第1个词,『我』这个单词是第2个词,那么『吴彦祖』就可以表示为一个 V 维全零向量、把第1个位置的0变成1,而『我』同样表示为 V 维全零向量、把第2个位置的0变成1。这样,每个词语都可以找到属于自己的唯一表示。
OK,那我们接下来就可以看看 Skip-gram 的网络结构了,x 就是上面提到的 one-hot encoder 形式的输入,y 是在这 V 个词上输出的概率,我们希望跟真实的 y 的 one-hot encoder 一样。
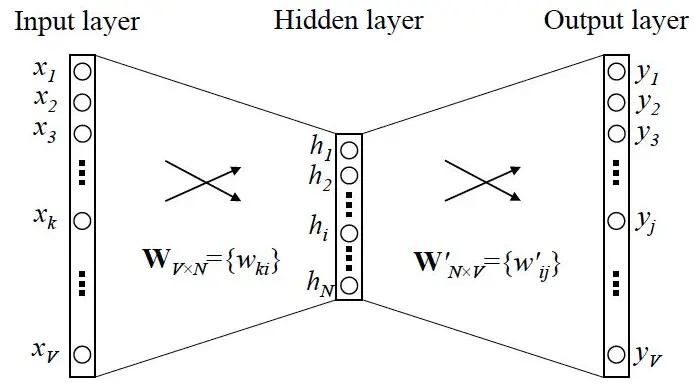
首先说明一点:隐层的激活函数其实是线性的,相当于没做任何处理(这也是 Word2vec 简化之前语言模型的独到之处),我们要训练这个神经网络,用反向传播算法,本质上是链式求导,在此不展开说明了,
首先说明一点:隐层的激活函数其实是线性的,相当于没做任何处理(这也是 Word2vec 简化之前语言模型的独到之处),我们要训练这个神经网络,用反向传播算法,本质上是链式求导,在此不展开说明了,
当模型训练完后,最后得到的其实是神经网络的权重,比如现在输入一个 x 的 one-hot encoder: [1,0,0,…,0],对应刚说的那个词语『吴彦祖』,则在输入层到隐含层的权重里,只有对应 1 这个位置的权重被激活,这些权重的个数,跟隐含层节点数是一致的,从而这些权重组成一个向量 vx 来表示x,而因为每个词语的 one-hot encoder 里面 1 的位置是不同的,所以,这个向量 vx 就可以用来唯一表示 x。
所以 Word2vec 本质上是一种降维操作——把词语从 one-hot encoder 形式的表示降维到 Word2vec 形式的表示。
隐层细节
假如词汇表长度为10000,首先使用one-hot形式表示每一个单词,经过隐层300个神经元计算,最后使用Softmax层对单词概率输出。每一对单词组,前者作为x输入,后者作为y标签。
假如我们想要学习的词向量维度为300,则需要将隐层的神经元个数设置为300(300是Google在其发布的训练模型中使用的维度,可调)。
隐层的权重矩阵就是词向量,我们模型学习到的就是隐层的权重矩阵。
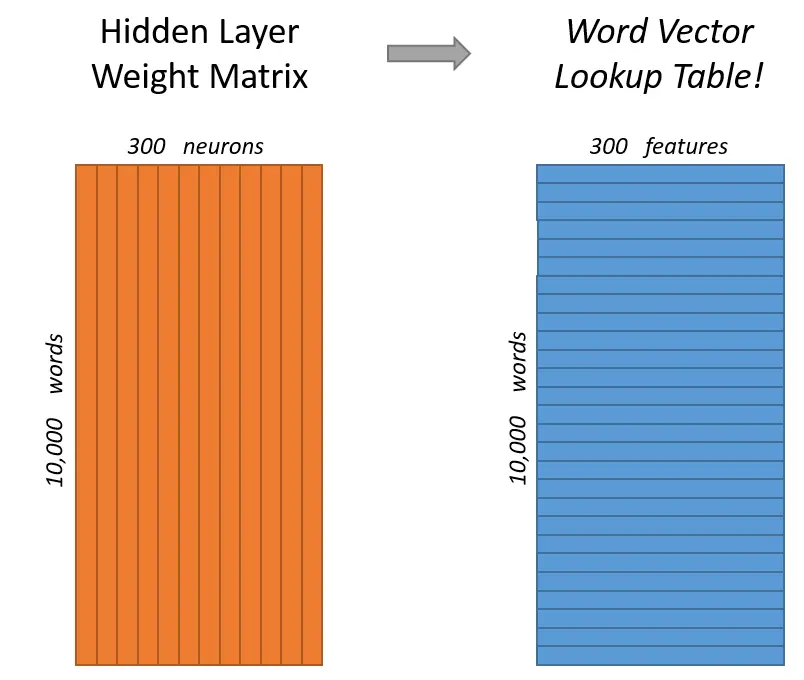
之所以这样,来看一下one-hot输入后与隐层的计算就明白了。
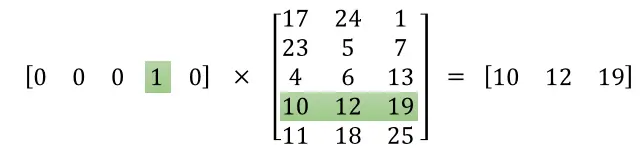
当使用One-hot去乘以矩阵的时候,会将某一行选择出来,即查表操作,所以权重矩阵是所有词向量组成的列表。
CBOW 详解:
CBOW 是 Continuous Bag-of-Words 的缩写,与神经网络语言模型不同的是,CBOW去掉了最耗时的非线性隐藏层
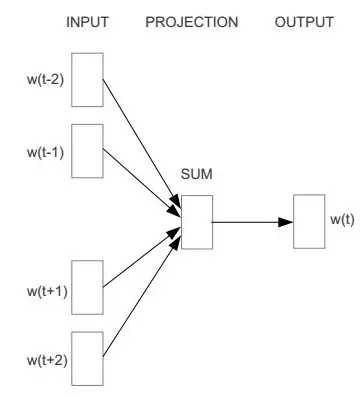
从图中可以看出,CBOW模型预测的是
,由于图中目标词
前后只取了各两个词,所以窗口的总大小是2。假设目标词
前后各取k个词,即窗口的大小是k,那么CBOW模型预测的将是
输入层到隐藏层
以图2为例,输入层是四个词的one-hot向量表示,分别为
(维度都为V x 1,V是模型的训练本文中所有词的个数),记输入层到隐藏层的权重矩阵为
(维度为V x d,d是认为给定的词向量维度),隐藏层的向量为
(维度为d x 1),那么
其实这里就是一个简单地求和平均。
隐藏层到输出层
记隐藏层到输出层的权重矩阵为
(维度为d x V),输出层的向量为
(维度为V x 1),那么
注意,输出层的向量
与输入层的向量为
虽然维度是一样的,但是
并不是one-hot向量,并且向量
中的每个元素都是有意义的。例如,我们假设训练样本只有一句话“I like to eat apple”,此刻我们正在使用 I、like、eat、apple 四个词来预测 to ,输出层的结果如图3所示。
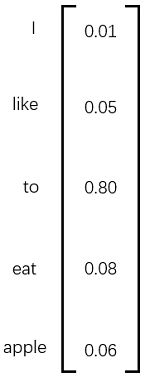 图3 向量y的例子
图3 向量y的例子
向量y中的每个元素表示我用 I、like、eat、apple 四个词预测出来的词是当元素对应的词的概率,比如是like的概率为0.05,是to的概率是0.80。由于我们想让模型预测出来的词是to,那么我们就要尽量让to的概率尽可能的大,所以我们目标是最大化函数
有了最大化的目标函数,我们接下来要做的就是求解这个目标函数,首先求
,然后求梯度,再梯度下降,具体细节在此省略,因为这种方法涉及到softmax层,softmax每次计算都要遍历整个词表,代价十分昂贵,所以实现的时候我们不用这种方法,次softmax或者负采样来替换掉输出层,降低复杂度。
优化方法
为了提高速度,Word2vec 经常采用 2 种加速方式:
Negative Sample(负采样)
- 本质是预测总体类别的一个子集
Hierarchical Softmax (层次Softmax, huffman树)
- 本质是把 N 分类问题变成 log(N)次二分类
Word2vec 的优缺点
需要说明的是:Word2vec 是上一代的产物(18 年之前), 18 年之后想要得到最好的效果,已经不使用 Word Embedding 的方法了,所以也不会用到 Word2vec。
优点:
- 由于 Word2vec 会考虑上下文,跟之前的 Embedding 方法相比,效果要更好(但不如 18 年之后的方法)
- 比之前的 Embedding方 法维度更少,所以速度更快
- 通用性很强,可以用在各种 NLP 任务中
缺点:
- 由于词和向量是一对一的关系,所以多义词的问题无法解决。
- Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化

问题
假如使用词向量维度为300,词汇量为10000个单词,那么神经网络输入层与隐层,隐层与输出层的参数量会达到惊人的300x10000=300万!训练如词庞大的神经网络需要庞大的数据量,还要避免过拟合。因此,Google在其第二篇论文中说明了训练的trick,其创新点如下:
- 将常用词对或短语视为模型中的单个”word”。
- 对频繁的词进行子采样以减少训练样例的数量。
- 在损失函数中使用”负采样(Negative Sampling)”的技术,使每个训练样本仅更新模型权重的一小部分。
子采样和负采样技术不仅降低了计算量,还提升了词向量的效果。
对频繁词子采样
在以上例子中,可以看到频繁单词’the’的两个问题:
- 对于单词对(‘fox’,’the’),其对单词’fox’的语义表达并没有什么有效帮助,’the’在每个单词的上下文中出现都非常频繁。
- 预料中有很多单词对(‘the’,…),我们应更好的学习单词’the’
Word2vec使用子采样技术来解决以上问题,根据单词的频次来削减该单词的采样率。以window size为10为例子,我们删除’the’:
- 当我们训练其余单词时候,’the’不会出现在他们的上下文中。
- 当中心词为’the’时,训练样本数量少于10。
负采样(Negative Sampling)
训练一个网络是说,计算训练样本然后轻微调整所有的神经元权重来提高准确率。换句话说,每一个训练样本都需要更新所有神经网络的权重。
就像如上所说,当词汇表特别大的时候,如此多的神经网络参数在如此大的数据量下,每次都要进行权重更新,负担很大。
在每个样本训练时,只修改部分的网络参数,负采样是通过这种方式来解决这个问题的。
当我们的神经网络训练到单词组(‘fox’, ‘quick’)时候,得到的输出或label都是一个one-hot向量,也就是说,在表示’quick’的位置数值为1,其它全为0。
负采样是随机选择较小数量的’负(Negative)’单词(比如5个),来做参数更新。这里的’负’表示的是网络输出向量种位置为0表示的单词。当然,’正(Positive)’(即正确单词’quick’)权重也会更新。
论文中表述,小数量级上采用5-20,大数据集使用2-5个单词。
我们的模型权重矩阵为300x10000,更新的单词为5个’负’词和一个’正’词,共计1800个参数,这是输出层全部3M参数的0.06%!!
负采样的选取是和频次相关的,频次越高,负采样的概率越大: $$P(w_i) = \frac{f(w_i)^{3/4}}{\sum_{j=0}^n(f(w_j)^{3/4})}$$ 论文选择0.75作为指数是因为实验效果好。C语言实现的代码很有意思:首先用索引值填充多次填充词汇表中的每个单词,单词索引出现的次数为$P(w_i) * \text{table_size}$。然后负采样只需要生成一个1到100M的整数,并用于索引表中数据。由于概率高的单词在表中出现的次数多,很可能会选择这些词。
GloVe 模型
模型目标:进行词的向量化表示,使得向量之间尽可能多地蕴含语义和语法的信息。
输入:语料库
输出:词向量
方法概述:首先基于语料库构建词的共现矩阵,然后基于共现矩阵和GloVe模型学习词向量。
Global Vector融合了矩阵分解的全局统计信息和上下文信息
常见的问题
1、文本表示哪些方法?
- 基于 one-hot、tf-idf、textrank 等的 bag-of-words;
- 主题模型:LSA(SVD)、pLSA、LDA;
- 基于词向量的固定表征:Word2vec、FastText、GloVe
- 基于词向量的动态表征:ELMo、GPT、BERT
2、怎么从语言模型理解词向量?怎么理解分布式假设?
上面给出的 4 个类型也是 nlp 领域最为常用的文本表示了,文本是由每个单词构成的,而谈起词向量,one-hot 是可认为是最为简单的词向量,但存在维度灾难和语义鸿沟等问题;通过构建共现矩阵并利用 SVD 求解构建词向量,则计算复杂度高;而早期词向量的研究通常来源于语言模型,比如 NNLM 和 RNNLM,其主要目的是语言模型,而词向量只是一个副产物。
所谓分布式假设,用一句话可以表达:相同上下文语境的词有似含义。而由此引申出了 Word2vec、FastText,在此类词向量中,虽然其本质仍然是语言模型,但是它的目标并不是语言模型本身,而是词向量,其所作的一系列优化,都是为了更快更好的得到词向量。GloVe 则是基于全局语料库、并结合上下文语境构建词向量,结合了 LSA 和 Word2vec 的优点。
3、传统的词向量有什么问题?怎么解决?各种词向量的特点是什么?
上述方法得到的词向量是固定表征的,无法解决一词多义等问题,如“川普”。为此引入基于语言模型的动态表征方法:ELMo、GPT、BERT。
各种词向量的特点:
- One-hot 表示 :维度灾难、语义鸿沟;
- 分布式表示 (distributed representation)
- 矩阵分解(LSA):利用全局语料特征,但 SVD 求解计算复杂度大;
- 基于 NNLM/RNNLM 的词向量:词向量为副产物,存在效率不高等问题;
- Word2vec、FastText:优化效率高,但是基于局部语料;
- GloVe:基于全局预料,结合了 LSA 和 Word2vec 的优点;
- ELMo、GPT、BERT:动态特征;
4、Word2vec 和 NNLM 对比有什么区别?(Word2vecvs NNLM)
1)其本质都可以看作是语言模型;
2)词向量只不过 NNLM 一个产物,Word2vec 虽然其本质也是语言模型,但是其专注于词向量本身,因此做了许多优化来提高计算效率:
- 与 NNLM 相比,词向量直接 sum,不再拼接,并舍弃隐层;
- 考虑到 sofmax 归一化需要遍历整个词汇表,采用 hierarchical softmax 和 negative sampling 进行优化,hierarchical softmax 实质上生成一颗带权路径最小的哈夫曼树,让高频词搜索路劲变小;negative sampling 更为直接,实质上对每一个样本中每一个词都进行负例采样;
5、Word2vec 和 FastText 对比有什么区别?(Word2vec vs FastText)
1)都可以无监督学习词向量, FastText 训练词向量时会考虑 subword;
2) FastText 还可以进行有监督学习进行文本分类,其主要特点:
- 结构与 CBOW 类似,但学习目标是人工标注的分类结果;
- 采用 hierarchical softmax 对输出的分类标签建立哈夫曼树,样本中标签多的类别被分配短的搜寻路径
- 引入 N-gram,考虑词序特征
- 引入 subword 来处理长词,处理未登陆词问题;
6、GloVe 和 Word2vec、 LSA 对比有什么区别?(Word2vecvs GloVe vs LSA)
1)GloVe vs LSA
LSA(Latent Semantic Analysis)可以基于 co-occurance matrix 构建词向量,实质上是基于全局语料采用 SVD 进行矩阵分解,然而 SVD 计算复杂度高;
GloVe 可看作是对 LSA 一种优化的高效矩阵分解算法,采用 Adagrad 对最小平方损失进行优化;
2)Word2vecvs GloVe
Word2vec 是局部语料库训练的,其特征提取是基于滑窗的;而 GloVe 的滑窗是为了构建 co-occurance matrix,是基于全局语料的,可见 GloVe 需要事先统计共现概率;因此,Word2vec 可以进行在线学习,GloVe 则需要统计固定语料信息。
Word2vec 是无监督学习,同样由于不需要人工标注;GloVe 通常被认为是无监督学习,但实际上 GloVe 还是有 label 的,即共现次数 [公式]。
Word2vec 损失函数实质上是带权重的交叉熵,权重固定;GloVe 的损失函数是最小平方损失函数,权重可以做映射变换。
总体来看,GloVe 可以被看作是更换了目标函数和权重函数的全局 Word2vec。
7、 Word2vec 的两种优化方法是什么?它们的目标函数怎样确定的?训练过程又是怎样的?
不经过优化的 CBOW 和 Skip-gram 中 , 在每个样本中每个词的训练过程都要遍历整个词汇表,也就是都需要经过 softmax 归一化,计算误差向量和梯度以更新两个词向量矩阵(这两个词向量矩阵实际上就是最终的词向量,可认为初始化不一样),当语料库规模变大、词汇表增长时,训练变得不切实际。为了解决这个问题,Word2vec 支持两种优化方法:hierarchical softmax 和 negative sampling。
(1)基于 hierarchical softmax 的 CBOW 和 Skip-gram
hierarchical softmax 使用一颗二叉树表示词汇表中的单词,每个单词都作为二叉树的叶子节点。对于一个大小为 V 的词汇表,其对应的二叉树包含 V-1 非叶子节点。假如每个非叶子节点向左转标记为 1,向右转标记为 0,那么每个单词都具有唯一的从根节点到达该叶子节点的由{0 1}组成的代号(实际上为哈夫曼编码,为哈夫曼树,是带权路径长度最短的树,哈夫曼树保证了词频高的单词的路径短,词频相对低的单词的路径长,这种编码方式很大程度减少了计算量)。
(2)基于 negative sampling 的 CBOW 和 Skip-gram
negative sampling 是一种不同于 hierarchical softmax 的优化策略,相比于 hierarchical softmax,negative sampling 的想法更直接——为每个训练实例都提供负例。
负采样算法实际上就是一个带权采样过程,负例的选择机制是和单词词频联系起来的。
具体做法是以 N+1 个点对区间 [0,1] 做非等距切分,并引入的一个在区间 [0,1] 上的 M 等距切分,其中 M » N。源码中取 M = 10^8。然后对两个切分做投影,得到映射关系:采样时,每次生成一个 [1, M-1] 之间的整数 i,则 Table(i) 就对应一个样本;当采样到正例时,跳过(拒绝采样)。