背景
今天,聊一个有趣的问题:拔掉网线几秒,再插回去,原本的 TCP 连接还存在吗?
可能有的同学会说,网线都被拔掉了,那说明物理层被断开了,那在上层的传输层理应也会断开,所以原本的 TCP 连接就不会存在了。就好像, 我们拨打有线电话的时候,如果某一方的电话线被拔了,那么本次通话就彻底断了。
真的是这样吗?
上面这个逻辑就有问题。问题在于,错误地认为拔掉网线这个动作会影响传输层,事实上并不会影响。
实际上,TCP 连接在 Linux 内核中是一个名为 struct socket 的结构体,该结构体的内容包含 TCP 连接的状态等信息。当拔掉网线的时候,操作系统并不会变更该结构体的任何内容,所以 TCP 连接的状态也不会发生改变。
我在我的电脑上做了个小实验,我用 ssh 终端连接了我的云服务器,然后我通过断开 wifi 的方式来模拟拔掉网线的场景,此时查看 TCP 连接的状态没有发生变化,还是处于 ESTABLISHED 状态。
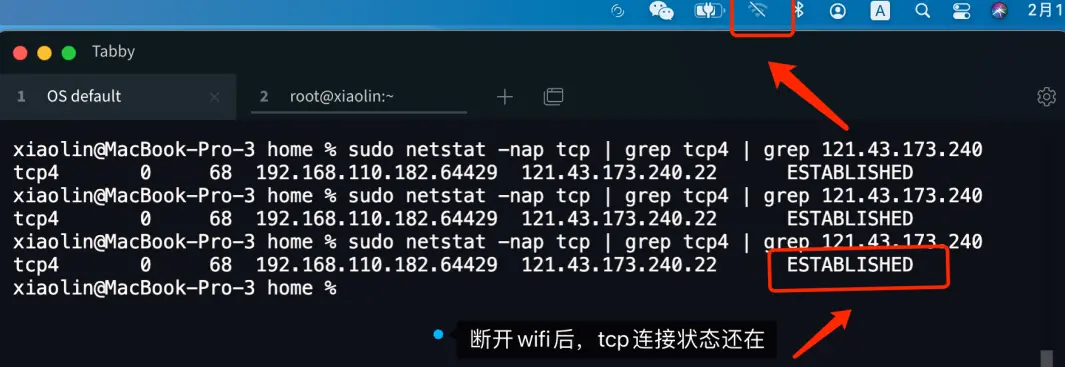
通过上面这个实验结果,我们知道了,拔掉网线这个动作并不会影响 TCP 连接的状态。 接下来,要看拔掉网线后,双方做了什么动作。 针对这个问题,要分场景来讨论:
- 拔掉网线后,有数据传输;
- 拔掉网线后,没有数据传输。
拔掉网线后,有数据传输
在客户端拔掉网线后,服务端向客户端发送的数据报文会得不到任何的响应,在等待一定时长后,服务端就会触发超时重传机制,重传未得到响应的数据报文。
如果在服务端重传报文的过程中,客户端刚好把网线插回去了,由于拔掉网线并不会改变客户端的 TCP 连接状态,并且还是处于 ESTABLISHED 状态,所以这时客户端是可以正常接收服务端发来的数据报文的,然后客户端就会回 ACK 响应报文。
此时,客户端和服务端的 TCP 连接依然存在,就感觉什么事情都没有发生。
但是,如果在服务端重传报文的过程中,客户端一直没有将网线插回去,服务端超时重传报文的次数达到一定阈值后,内核就会判定出该 TCP 有问题,然后通过 Socket 接口告诉应用程序该 TCP 连接出问题了,于是服务端的 TCP 连接就会断开。
而等客户端插回网线后,如果客户端向服务端发送了数据,由于服务端已经没有与客户端相同四元组的 TCP 连接了,因此服务端内核就会回复 RST 报文,客户端收到后就会释放该 TCP 连接。
此时,客户端和服务端的 TCP 连接都已经断开了。
那 TCP 的数据报文具体重传几次呢?
在 Linux 系统中,提供了一个叫 tcp_retries2 配置项,默认值是 15,如下:
| |
这个内核参数是控制,在 TCP 连接建立的情况下,超时重传的最大次数。
不过 tcp_retries2 设置了 15 次,并不代表 TCP 超时重传了 15 次才会通知应用程序终止该 TCP 连接,内核还会基于「最大超时时间」来判定。
每一轮的超时时间都是倍数增长的,比如第一次触发超时重传是在 2s 后,第二次则是在 4s 后,第三次则是 8s 后,以此类推。
内核会根据 tcp_retries2 设置的值,计算出一个最大超时时间。
在重传报文且一直没有收到对方响应的情况时,先达到「最大重传次数」或者「最大超时时间」这两个的其中一个条件后,就会停止重传,然后就会断开 TCP 连接。
拔掉网线后,没有数据传输。
针对拔掉网线后,没有数据传输的场景,还得看是否开启了 TCP keepalive 机制 (TCP 保活机制)。
如果没有开启 TCP keepalive 机制,在客户端拔掉网线后,并且双方都没有进行数据传输,那么客户端和服务端的 TCP 连接将会一直保持存在。
而如果开启了 TCP keepalive 机制,在客户端拔掉网线后,即使双方都没有进行数据传输,在持续一段时间后,TCP 就会发送探测报文:
- 如果对端是正常工作的。当 TCP 保活的探测报文发送给对端,对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
- 如果对端主机崩溃,或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。 所以,TCP 保活机制可以在双方没有数据交互的情况,通过探测报文,来确定对方的 TCP 连接是否存活。
TCP keepalive 机制具体是怎么样的?
这个机制的原理是这样的: 定义一个时间段,在这个时间段内,如果没有任何连接相关的活动,TCP 保活机制会开始作用,每隔一个时间间隔,发送一个探测报文,该探测报文包含的数据非常少,如果连续几个探测报文都没有得到响应,则认为当前的 TCP 连接已经死亡,系统内核将错误信息通知给上层应用程序。
在 Linux 内核有对应的参数可以设置保活时间、保活探测的次数、保活探测的时间间隔,以下都为默认值:
| |
- tcp_keepalive_time=7200:表示保活时间是 7200 秒(2小时),也就 2 小时内如果没有任何连接相关的活动,则会启动保活机制;
- tcp_keepalive_intvl=75:表示每次检测间隔 75 秒;
- tcp_keepalive_probes=9:表示检测 9 次无响应,认为对方是不可达的,从而中断本次的连接。
也就是说在 Linux 系统中,最少需要经过 2 小时 11 分 15 秒才可以发现一个「死亡」连接。
tcp_keepalive_time + tcp_keepalive_intvl * tcp_keepalive_probes ==> 7200 + 75 * 9 =7879s (2h11min15s)
注意,应用程序若想使用 TCP 保活机制,需要通过 socket 接口设置 SO_KEEPALIVE 选项才能够生效,如果没有设置,那么就无法使用 TCP 保活机制。
TCP keepalive 机制探测的时间也太长了吧?
对的,是有点长。
TCP keepalive 是 TCP 层(内核态) 实现的,它是给所有基于 TCP 传输协议的程序一个兜底的方案。
实际上,我们应用层可以自己实现一套探测机制,可以在较短的时间内,探测到对方是否存活。
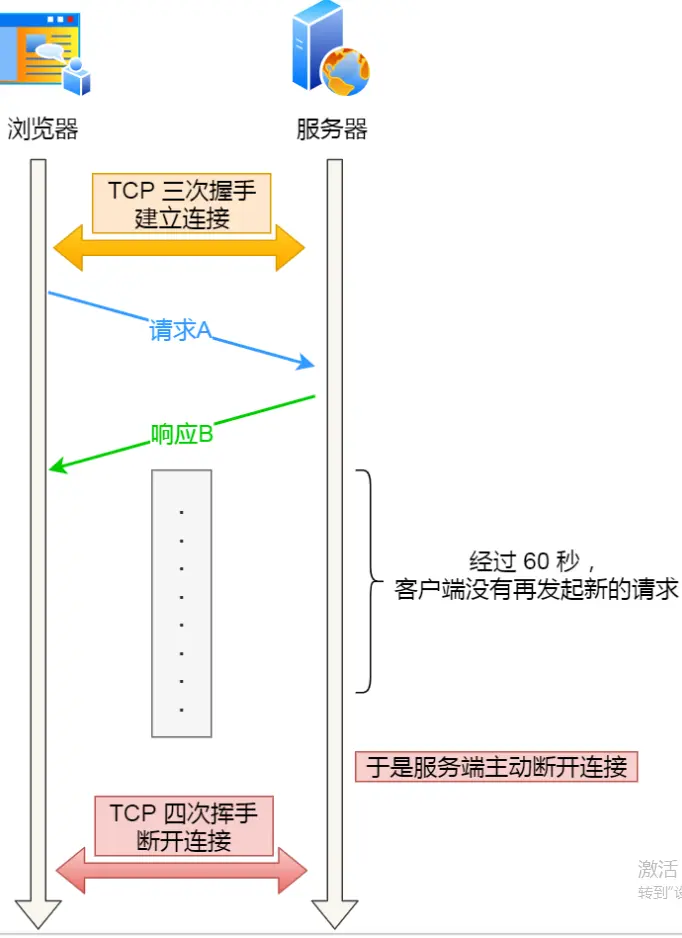
比如,web 服务软件一般都会提供 keepalive_timeout 参数,用来指定 HTTP 长连接的超时时间。如果设置了 HTTP 长连接的超时时间是 60 秒,web 服务软件就会启动一个定时器,如果客户端在发完一个 HTTP 请求后,在 60 秒内都没有再发起新的请求,定时器的时间一到,就会触发回调函数来释放该连接。
总结
客户端拔掉网线后,并不会直接影响 TCP 连接状态。所以,拔掉网线后,TCP 连接是否还会存在,关键要看拔掉网线之后,有没有进行数据传输。
有数据传输的情况:
在客户端拔掉网线后,如果服务端发送了数据报文,那么在服务端重传次数没有达到最大值之前,客户端就插回了网线,那么双方原本的 TCP 连接还是能正常存在,就好像什么事情都没有发生。
在客户端拔掉网线后,如果服务端发送了数据报文,在客户端插回网线之前,服务端重传次数达到了最大值时,服务端就会断开 TCP 连接。等到客户端插回网线后,向服务端发送了数据,因为服务端已经断开了与客户端相同四元组的 TCP 连接,所以就会回 RST 报文,客户端收到后就会断开 TCP 连接。至此, 双方的 TCP 连接都断开了。
没有数据传输的情况:
- 如果双方都没有开启 TCP keepalive 机制,那么在客户端拔掉网线后,如果客户端一直不插回网线,那么客户端和服务端的 TCP 连接状态将会一直保持存在。
- 如果双方都开启了 TCP keepalive 机制,那么在客户端拔掉网线后,如果客户端一直不插回网线,TCP keepalive 机制会探测到对方的 TCP 连接没有存活,于是就会断开 TCP 连接。而如果在 TCP 探测期间,客户端插回了网线,那么双方原本的 TCP 连接还是能正常存在。
除了客户端拔掉网线的场景,还有客户端「宕机和杀死进程」的两种场景。
第一个场景,客户端宕机这件事跟拔掉网线是一样无法被服务端感知的,所以如果在没有数据传输,并且没有开启 TCP keepalive 机制时,服务端的 TCP 连接将会一直处于 ESTABLISHED 连接状态,直到服务端重启进程。
所以,我们可以得知一个点。在没有使用 TCP 保活机制,且双方不传输数据的情况下,一方的 TCP 连接处在 ESTABLISHED 状态时,并不代表另一方的 TCP 连接还一定是正常的。
第二个场景,杀死客户端的进程后,客户端的内核就会向服务端发送 FIN 报文,与客户端进行四次挥手。
所以,即使没有开启 TCP keepalive,且双方也没有数据交互的情况下,如果其中一方的进程发生了崩溃,这个过程操作系统是可以感知得到的,于是就会发送 FIN 报文给对方,然后与对方进行 TCP 四次挥手。
扩展
TCP重置报文段及RST常见场景分析
RST表示连接重置,用于关闭那些已经没有必要继续存在的连接。一般情况下表示异常关闭连接,区别与四次分手正常关闭连接。
我们知道TCP建立连接的时候需要三次连接,TCP释放连接的时候需要四次挥手,在这个过程中,出现了很多特殊的标志报文段,例如SYN ACK FIN,在TCP协议中,除了上面说了那些标志报文段之外,还有其他的报文段,如PUSH标志报文段以及今天需要重点讲解的RST报文段。
RST:(Reset the connection)用于复位因某种原因引起出现的错误连接,也用来拒绝非法数据和请求。如果接收到RST位时候,通常发生了某些错误;
发送RST包关闭连接时,不必等缓冲区的包都发出去,直接就丢弃缓冲区中的包,发送RST;接收端收到RST包后,也不必发送ACK包来确认。
“Connection reset”的原因是服务器关闭了Connection[调用了Socket.close()方法]。大家可能有疑问了:服务器关闭了Connection为什么会返回“RST”而不是返回“FIN”标志。原因在于Socket.close()方法的语义和TCP的“FIN”标志语义不一样: 发送TCP的“FIN”标志表示我不再发送数据了,而Socket.close()表示我不在发送也不接受数据了。问题就出在“我不接受数据” 上,如果此时客户端还往服务器发送数据,服务器内核接收到数据,但是发现此时Socket已经close了,则会返回“RST”标志给客户端。当然,此时客户端就会提示:“Connection reset”。
产生RST的三个条件是:
- 目的地 为某端口的SYN到达,然而在该端口上并没有正在监听的服务器;
- TCP想取消一个已有连接;
- TCP接收到一个根本不存在的连接上的分节。
Connection reset 与 Connection reset by peer
- 服务器返回了 “RST” 时,如果此时客户端正在从 Socket 套接字的输出流中读数据则会提示 Connection reset ;
A向B发起连接,但B之上并未监听相应的端口,这时B操作系统上的 TCP 处理程序会发 RST 包。
- 服务器返回了 “RST” 时,如果此时客户端正在往 Socket 套接字的输入流中写数据则会提示 Connection reset by peer 。
AB正常建立连接了,正在通讯时,A向B发送了FIN包要求关连接,B发送ACK后,网断了,A通过若干原因放弃了这个连接(例如进程重启)。 等网络恢复之后,B又开始发数据包(客户端并不知道,服务器已经忘记三次握手了),A收到后表示压力很大,不知道这野连接哪来的,就发了个RST包强制把连接关了,B收到后会出现 connect reset by peer 错误。
需要注意的是,服务端有两种情况不会发送RST:
服务器关机: 会断开 TCP 连接,会发送 FIN 数据报
服务器主机崩溃的状态 如果,客户端和服务器已经建立了连接的时候,此时服务器崩溃(达到这一标准可以把服务器的网线拔掉,这个时候,服务器就不能发送 FIN 数据报了,和关机不一样的)
此时如果客户端向服务器发送数据的时候,因为服务器已经不存在了,那么客户端就不能接受到服务器给客户端的 ack 信息,这个时候,客户端建立的是 TCP 连接,就会重发数据报,发送多少次之后就会返回超时,也就是 ETIMEOUT 。
ETIMEOUT:当connect调用的时候会进行三次握手,如果客户端没有收到服务器对SYN的ACK数据报,就会返回ETIMEOUT(客户端在返回这个错误之前会重发SYN数据报)
前面谈到了导致 “Connection reset” 的原因,而具体的解决方案有如下几种:
- 出错了重试;
- 客户端和服务器统一使用TCP长连接;
- 客户端和服务器统一使用TCP短连接。
首先是出错了重试:这种方案可以简单防止 “Connection reset” 错误,然后如果服务不是 “幂等” 的则不能使用该方法;比如提交订单操作就不是幂等的,如果使用重试则可能造成重复提单。
然后是客户端和服务器统一使用 TCP 长连接:客户端使用 TCP 长连接很容易配置(直接设置HttpClient就好),而服务器配置长连接就比较麻烦了,就拿tomcat来说,需要设置 tomcat 的 maxKeepAliveRequests 、connectionTimeout 等参数。另外如果使用了 nginx 进行反向代理或负载均衡,此时也需要配置 nginx 以支持长连接(nginx默认是对客户端使用长连接,对服务器使用短连接,详见 keepalived 相关指令)。
使用长连接可以避免每次建立 TCP 连接的三次握手而节约一定的时间,但是我这边由于是内网,客户端和服务器的 3 次握手很快,大约只需1ms。ping一下大约0.93ms(一次往返);三次握手也是一次往返(第三次握手不用返回)。根据80/20原理,1ms可以忽略不计;又考虑到长连接的扩展性不如短连接好、修改nginx和tomcat的配置代价很大(所有后台服务都需要修改);所以这里并没有使用长连接。
小结
- Connection reset,远程主机没有监听这个端口、连接,可以是:
- 服务端已关闭,客户端仍旧请求,服务端返回Rst;
- 服务端未监听该端口,客户端请求,服务端返回Rst;
- Connection reset by peer,是远程主机强迫关闭了一个现有的连接,可以是:
- 客户端断网重连,服务端返回Rst;
- 服务端进程崩溃后重启,向先前的客户端返回Rst,并等待下次重新与客户端建连;