CPU缓存
CPU缓存(CPU Cache)的目的是为了提高访问内存(RAM)的效率,这虽然已经涉及到硬件的领域,但它仍然与我们息息相关,了解了它的一些原理,能让我们写出更高效的程序,另外在多线程程序中,一些不可思议的问题也与缓存有关。
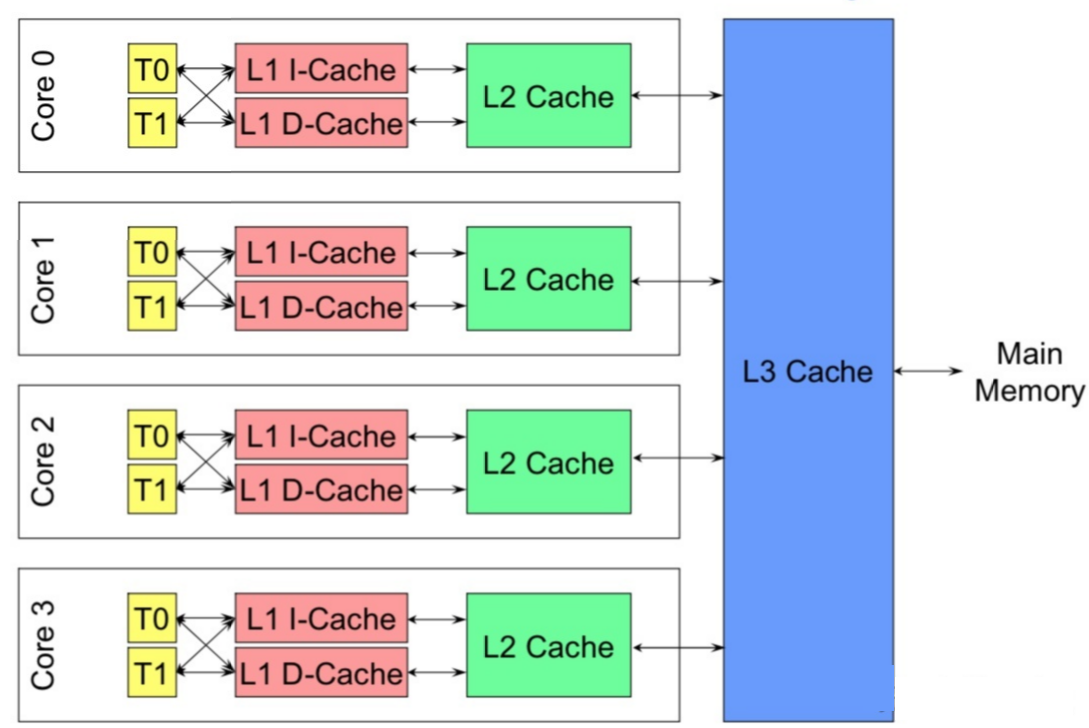
现代多核处理器,一个CPU由多个核组成,每个核又可以有多个硬件线程,比如我们说4核8线程,就是指有4个核,每个核2个线程,这在OS看来就像8个并行处理器一样。
CPU缓存有多级缓存,比如L1, L2, L3等:
- L1容量最小,速度最快,每个核都有L1缓存,L1又专门针对指令和数据分成L1d(数据缓存),L1i(指令缓存)。
- L2容量比L1大,速度比L1慢,每个核都有L2缓存。
- L3容量最大,速度最慢,多个核共享一个L3缓存。
有些CPU可能还有L4缓存,不过不常见;此外还有其他类型的缓存,比如TLB(translation lookaside buffer),用于物理地址和虚拟地址转译,这不是我们关心的缓存。
下图展示了缓存和CPU的关系:
Linux用下面命令可以查看CPU缓存的信息:
| |
- 上面显示CPU只有3级缓存,L4都为0。
- L1的数据缓存和指令缓存分别是32KB;L2为256KB;L3为30MB。
- 在缓存和主存之间,数据是按固定大小的块传输的 该块称为缓存行(cache line),这里显示每行的大小为64Bytes。
- ASSOC表示主存地址映射到缓存的策略,这里L1是8路组相联,L2是16路组联,L3是11路组相联,稍后解释是什么意思。
缓存结构
一块CPU缓存可以看成是一个数组,数组元素是缓存项(cache entry),一个缓存项的内容大概是这样的:
| |
- data block就是从内存中拷贝过来的数据,也就是我们说的cache line,从上面信息可知大小是64字节。
- tag 保存了内存地址的一部分,是用来验证是否缓存命中的。
- flag 是一些标志位,比如缓存是否失效,写dirty等等。
- 实际上LEVEL1_ICACHE_SIZE这个数据,是用data block来算的,并不包括tag和flag占用的大小,比如64 x 512 = 32768,表示LEVEL1_ICACHE_SIZE可以缓存512个cache line。
缓存首先要解决的问题是:怎么映射内存地址和缓存地址?比如CPU要检查一个内存值是否已经缓存,那么它首先要能算出这个内存地址对应的缓存地址,然后才能检查。
为了解决这个问题,缓存将一个内存地址分成下面几个部分:
| |
- tag和缓存项中的tag对应,用来验证是否缓存命中的。
- index 缓存项数组中的索引。
- offset 缓存块(cache line)中的偏移,因为缓存块是64字节,而内存值可能只有4个字节,一个缓存块可以保存多个连续的内存值。这个offset实际上就是指明内存值在cache line中的位置。
直接映射缓存
现在我们举一个具体的例子,说明内存和缓存是如何映射的:
- 假如缓存的大小是32768B(32KB),缓存块大小是64Bytes,那么缓存项数组就有 32768/64=512 个。
- CPU要访问一个内存地址0x1CAABBDD,它首先检查这个内存地址是否在缓存中,检查过程是这样的: 内存地址的二进制形式是(低位在前面):
| |
- 先计算内存在cache line中的偏移,因为缓存块是64字节,那么offset需要占6位(2^6=64),即offset=011101=29。 -= 接着要计算缓存项的索引,因为缓存项数组是512个,所以index需要占9位(2^9=512),即index=011101111=239。
- 现在我们通过offset和index已经找到缓存块的具体位置了,但是因为内存要远比缓存大很多,所以多个内存块是可以映射到同一个位置的,怎么判断这个缓存块位置存的就是这个内存的值呢?答案就是tag:内存地址去掉index和offset的部分,剩下的就是tag=00011100101010101=0x3955。
- 通过index找到缓存项,比较缓存项中的tag是否与内存地址中的tag相同,如果相同表示命中,就直接取缓存块中的值;如果不同表示未命中,CPU需要将内存值拷贝到缓存(替换掉老的)
这种映射方式就称为直接映射(Direct mapped),它的缺点就是多个内存地址会映射到同一个缓存地址,拿上面的内存地址来看,只要offset和index相同的内存地址,就一定会映射到同一个地方,比如:
| |
如果同时访问上面3个地址,就会一直替换缓存的值,也就是一直出现缓存冲突,这可能比没有缓存还要慢,因为除了访问内存外,还多一个拷贝内存值到缓存的操作。
N路组联
为了解决上面的问题,我试着把缓存项数组分成2个数组(2路),比如分成2个256的数组,如下图所示:
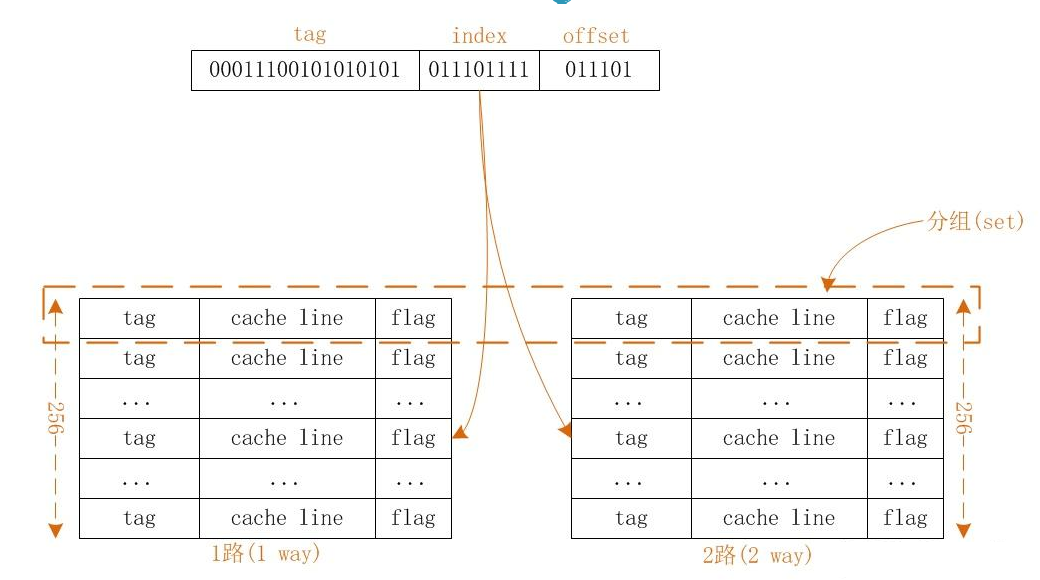
查找过程和上面其实一样的:
- 先通过index找到数组索引,只不过因为是2路,所以存在2个数组。
- 然后通过内存tag依次比较2个缓存顶的tag,如果其中一个tag相等,说明这个数组缓存命中;如果两个都不相等,说明缓存不命中,CPU会拷贝内存值到缓存中,但是现在有2个位置,要拷贝进哪个呢?我的理解CPU应该是随机选1路拷贝。
- offset这个其实无关紧要,因为它是cache line中的偏移。
那这个和直接映射相比,好在哪里呢,因为一个内存值会随机拷贝到2路中的1个,所以缓存冲突(多个内存地址映射到同一个缓存地址)的概率会降低一半;如果把缓存项数组分成4个数组,这就是4路组相联。
上面LEVEL1_ICACHE_ASSOC的值等于8,表明是8路组相联。分组越多,缓存冲突率越低,但是CPU要遍历的数组就越多,这是一个权衡的问题。
通过观察也可以发现,其实直接映射就是1路组相联。如果直接分成512个数组,那每个数组只有1项,这种就是全相联,CPU直接遍历512个数组,判断内存地址在哪1个。
缓存分配策略和更新策略
当CPU从内存读数据时,如果该数据没有在缓存中(read miss),CPU会把数据拷贝到缓存。
当CPU往内存写数据时: 有多种写策略:
如果在写的时候数在缓存中
- Write through 更新缓存的数据,同时更新内存的数据。
- Write back 只更新缓存的数据,同时在缓存项设置一个drity标志位,内存的数据只会在某个时刻更新(比如替换cache line时)。
如果在写的时候数据没有在缓存中(write miss),也有两种策略:
- Write allocate 在写之前先把数据加载到缓存,然后再实施上面的写策略。
- No-write allocate 不加载缓存,直接把数据写到内存。数据只有在 read miss 时才会加载到缓存。
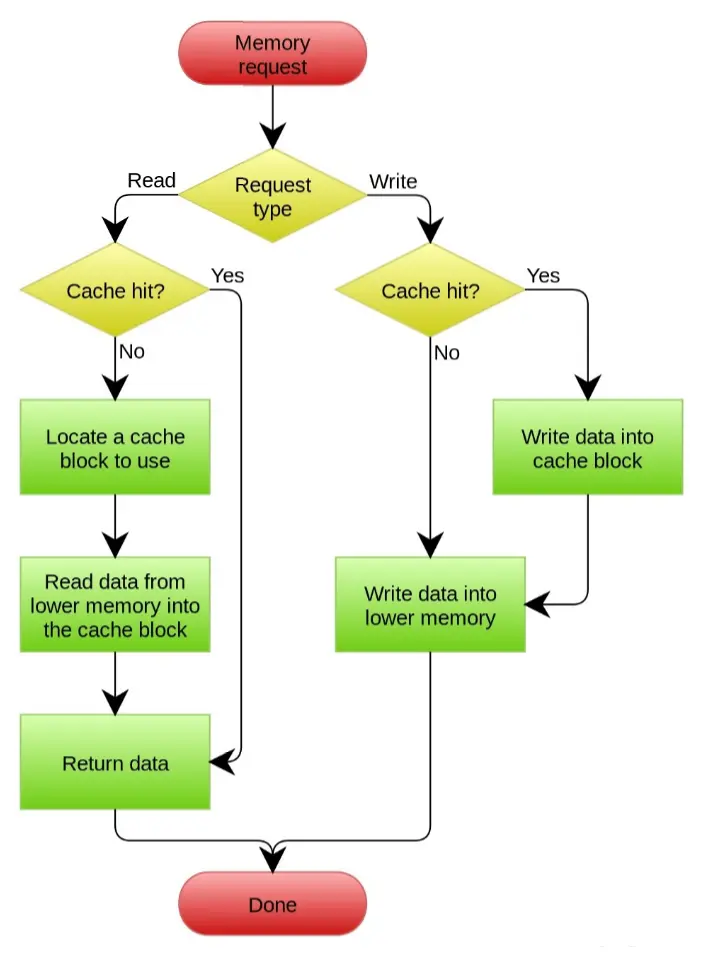
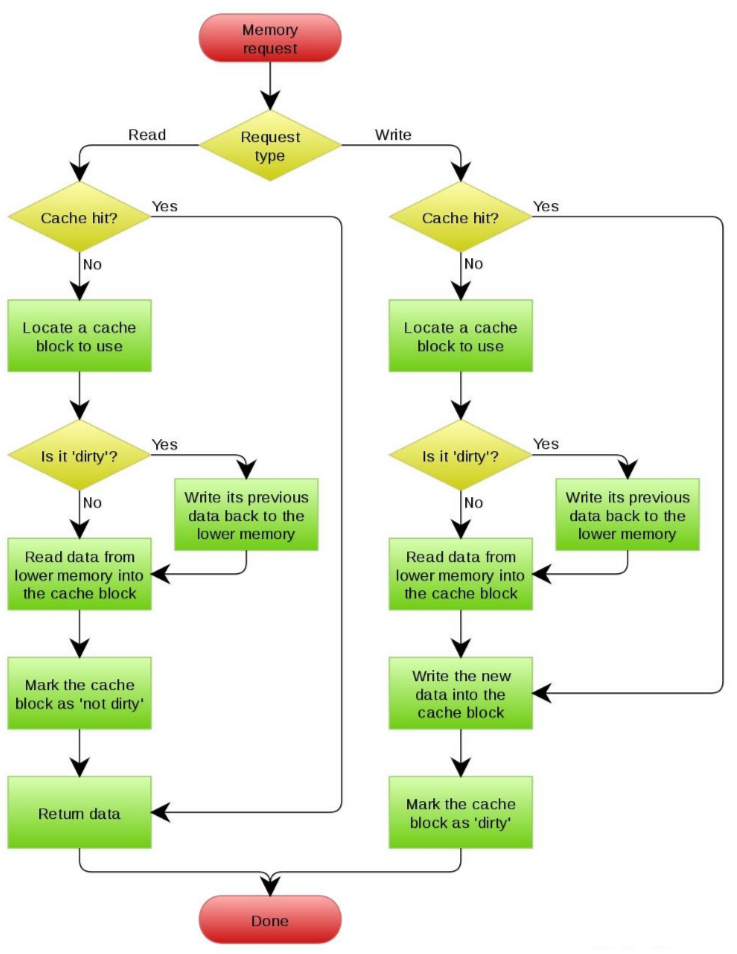
虽然上面两组策略可以任意搭配,但通常情况下是 No-write allocate 和 Write through 一起使用,而 Write allocate 则和 Write back 一起使用,下面是 wikipedia 的两张流程图。
No-write allocate方式的 Write through Cache:
Write allocate 方式的 Write back Cache
从上面描述我们知道,当我们向一个内存写数据时,内存中的数据可能不马上被更新,这个新数据可能还在cache line呆着。因为每个核都有自己的缓存,如果CPU不做处理,可以想象一定会出问题的:比如核1改了数据,核2去读同一个数据,此时数据还在核1的缓存中,核2读到的就是老的数据。CPU为了处理多核间的缓存同步,有一套复杂的一致性协议。关于这个后面再来学习。
其他:Cache Aside(旁路缓存)策略
我们来考虑一种最简单的业务场景,比方说在你的电商系统中有一个用户表,表中只有 ID 和年龄两个字段,缓存中我们以 ID 为 Key 存储用户的年龄信息。那么当我们要把 ID 为 1 的用户的年龄从 19 变更为 20,要如何做呢?
你可能会产生这样的思路:先更新数据库中 ID 为 1 的记录,再更新缓存中 Key 为 1 的数
据。
这个思路会造成缓存和数据库中的数据不一致。比如,A 请求将数据库中 ID 为 1 的用户年
龄从 19 变更为 20,与此同时,请求 B 也开始更新 ID 为 1 的用户数据,它把数据库中记
录的年龄变更为 21,然后变更缓存中的用户年龄为 21。紧接着,A 请求开始更新缓存数
据,它会把缓存中的年龄变更为 20。此时,数据库中用户年龄是 21,而缓存中的用户年龄
却是 20。
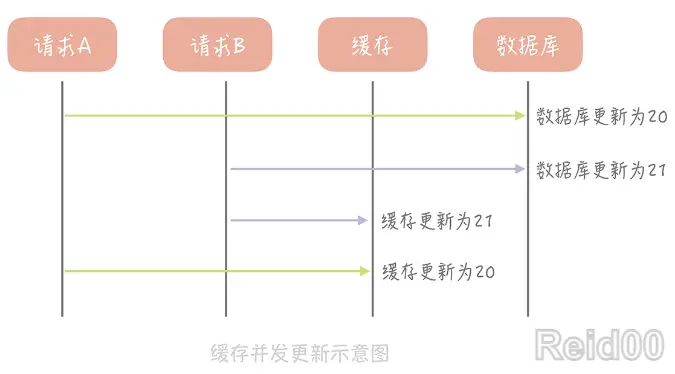
为什么产生这个问题呢?因为变更数据库和变更缓存是两个独立的操作,而我们并
没有对操作做任何的并发控制。那么当两个线程并发更新它们的时候,就会因为写入顺序的不
同造成数据的不一致。
另外,直接更新缓存还存在另外一个问题就是丢失更新。还是以我们的电商系统为例,假如 电商系统中的账户表有三个字段:ID、户名和金额,这个时候缓存中存储的就不只是金额 信息,而是完整的账户信息了。当更新缓存中账户金额时,你需要从缓存中查询完整的账户 数据,把金额变更后再写入到缓存中。
这个过程中也会有并发的问题,比如说原有金额是 20,A 请求从缓存中读到数据,并且把 金额加 1,变更成 21,在未写入缓存之前又有请求 B 也读到缓存的数据后把金额也加 1, 也变更成 21,两个请求同时把金额写回缓存,这时缓存里面的金额是 21,但是我们实际上 预期是金额数加 2,这也是一个比较大的问题。
那我们要如何解决这个问题呢?其实,我们可以在更新数据时不更新缓存,而是删除缓存中
的数据,在读取数据时,发现缓存中没了数据之后,再从数据库中读取数据,更新到缓存
中。
这个策略就是我们使用缓存最常见的策略,Cache Aside 策略(也叫旁路缓存策略),这
个策略数据以数据库中的数据为准,缓存中的数据是按需加载的。它可以分为读策略和写策
略,其中读策略的步骤是:
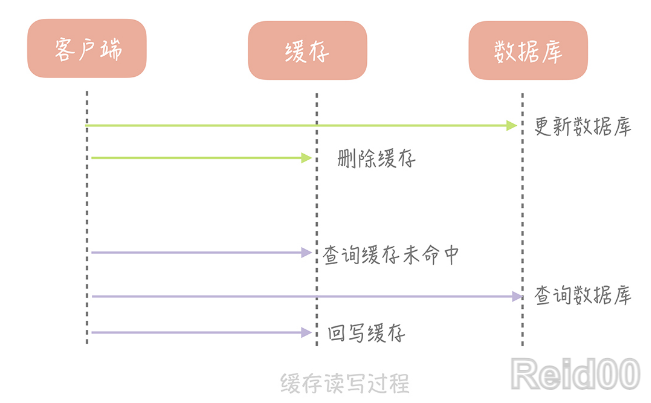
从缓存中读取数据
- 如果缓存命中,则直接返回数据;
- 如果缓存不命中,则从数据库中查询数据;
- 查询到数据后,将数据写入到缓存中,并且返回给用户。
写策略的步骤是:
- 更新数据库中的记录;
- 删除缓存记录。
你也许会问了,在写策略中,能否先删除缓存,后更新数据库呢?答案是不行的,因为这样
也有可能出现缓存数据不一致的问题,我以用户表的场景为例解释一下。
假设某个用户的年龄是 20,请求 A 要更新用户年龄为 21,所以它会删除缓存中的内容。 这时,另一个请求 B 要读取这个用户的年龄,它查询缓存发现未命中后,会从数据库中读取 到年龄为 20,并且写入到缓存中,然后请求 A 继续更改数据库,将用户的年龄更新为 21,这就造成了缓存和数据库的不一致。
那么像 Cache Aside 策略这样先更新数据库,后删除缓存就没有问题了吗?其实在理论上
还是有缺陷的。假如某个用户数据在缓存中不存在,请求 A 读取数据时从数据库中查询到
年龄为 20,在未写入缓存中时另一个请求 B 更新数据。它更新数据库中的年龄为 21,并
且清空缓存。这时请求 A 把从数据库中读到的年龄为 20 的数据写入到缓存中,造成缓存
和数据库数据不一致。
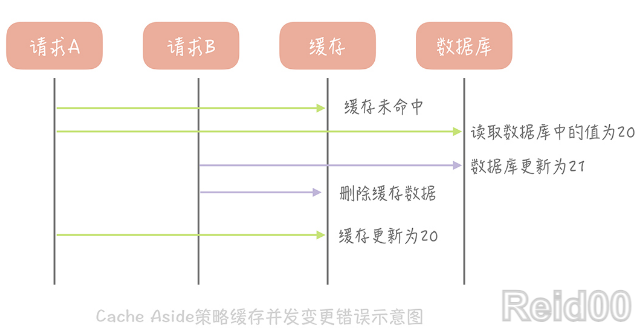
不过这种问题出现的几率并不高,原因是缓存的写入通常远远快于数据库的写入,所以在实
际中很难出现请求 B 已经更新了数据库并且清空了缓存,请求 A 才更新完缓存的情况。而一
旦请求 A 早于请求 B 清空缓存之前更新了缓存,那么接下来的请求就会因为缓存为空而
从数据库中重新加载数据,所以不会出现这种不一致的情况。
Cache Aside 策略是我们日常开发中最经常使用的缓存策略,不过我们在使用时也要学会
依情况而变。比如说当新注册一个用户,按照这个更新策略,你要写数据库,然后清理缓存
(当然缓存中没有数据给你清理)。可当我注册用户后立即读取用户信息,并且数据库主从
分离时,会出现因为主从延迟所以读不到用户信息的情况。
而解决这个问题的办法恰恰是在插入新数据到数据库之后写入缓存,这样后续的读请求就会
从缓存中读到数据了。并且因为是新注册的用户,所以不会出现并发更新用户信息的情况。
Cache Aside 存在的最大的问题是当写入比较频繁时,缓存中的数据会被频繁地清理,这
样会对缓存的命中率有一些影响。如果你的业务对缓存命中率有严格的要求,那么可以考虑
两种解决方案:
一种做法是在更新数据时也更新缓存,只是在更新缓存前先加一个分布式锁,因为这样 在同一时间只允许一个线程更新缓存,就不会产生并发问题了。当然这么做对于写入的性能 会有一些影响;
另一种做法同样也是在更新数据时更新缓存,只是给缓存加一个较短的过期时间,这样 即使出现缓存不一致的情况,缓存的数据也会很快地过期,对业务的影响也是可以接受。 当然了,除了这个策略,在计算机领域还有其他几种经典的缓存策略,它们也有各自适用的 使用场景。