简介LSM Tree
MySQL、etcd 等存储系统都是面向读多写少场景的,其底层大都采用 B-Tree 及其变种数据结构。而 LSM-Tree 则解决了另一个应用场景——写多读少时面临的问题。在面对亿级的海量数据的存储和检索的场景下,我们通常选择强力的 NoSQL 数据库,如 Hbase、RocksDB 等,它们的文件组织方式,都是仿照 LSM-Tree 实现的。 reference
LSM-Tree 全称是 Log Structured Merge Tree,是一种分层、有序、面向磁盘的数据结构,其核心思想是充分利用磁盘的顺序写性能要远高于随机写性能这一特性,将批量的随机写转化为一次性的顺序写。
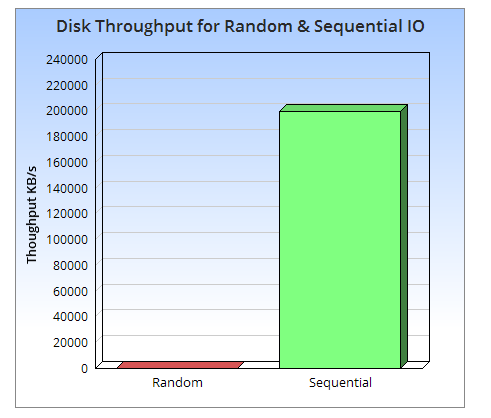 从上图可以直观地看出,磁盘的顺序访问速度至少比随机 I/O 快三个数量级,甚至顺序访问磁盘比随机访问主内存还要快。这意味着要尽可能避免随机 I/O 操作,顺序访问非常值得我们去探讨与设计。
从上图可以直观地看出,磁盘的顺序访问速度至少比随机 I/O 快三个数量级,甚至顺序访问磁盘比随机访问主内存还要快。这意味着要尽可能避免随机 I/O 操作,顺序访问非常值得我们去探讨与设计。
LSM-Tree 围绕这一原理进行设计和优化,通过消去随机的更新操作来达到这个目的,以此让写性能达到最优,同时为那些长期具有高更新频率的文件提供低成本的索引机制,减少查询时的开销。
Two-Component LSM-Tree
LSM-Tree 可以由两个或多个类树的数据结构组件构成,本小节我们先介绍较为简单的两组件情况。
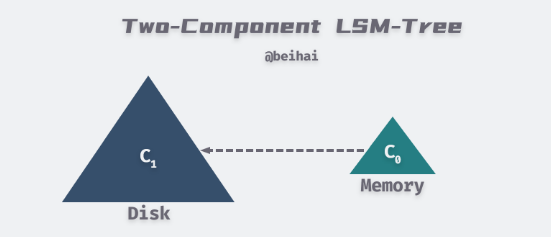
两组件 LSM-Tree(Two-Component LSM-Tree)在内存中有一个 C0 组件,它可以是 AVL 或 SkipList 等结构,所有写入首先写到 C0 中。而磁盘上有一个 C1 组件,当 C0 组件的大小达到阈值时,就需要进行 Rolling Merge,将内存中的内容合并到 C1 中。两组件 LSM-Tree 的写操作流程如下:
- 当有写操作时,会先将数据追加写到日志文件中,以备必要时恢复;
- 然后将数据写入位于内存的 C0 组件,通过某种数据结构保持 Key 有序;
- 内存中的数据定时或按固定大小刷新到磁盘,更新操作只写到内存,并不更新磁盘上已有文件;
- 随着写操作越来越多,磁盘上积累的文件也越来越多,这些文件不可写但有序,所以我们定时对文件进行合并(Compaction)操作,消除冗余数据,减少文件数量。
类似于普通的日志写入方式,这种数据结构的写入,全部都是以Append的模式追加,不存在删除和修改。对于任何应用来说,那些会导致索引值发生变化的数据更新都是繁琐且耗时的,但是这样的更新却可以被 LSM-Tree 轻松地解决,将该更新操作看做是一个删除操作加上一个插入操作。
C1 组件是为顺序性的磁盘访问优化过的,可以是 B-Tree 一类的数据结构(LevelDB 中的实现是 SSTable),所有的节点都是 100% 填充,为了有效利用磁盘,在根节点之下的所有的单页面节点都会被打包放到连续的多页面磁盘块(Multi-Page Block)上。对于 Rolling Merge 和长区间检索的情况将会使用 Multi-Page Block I/O,这样就可以有效减少磁盘旋臂的移动;而在匹配性的查找中会使用 Single-Page I/O,以最小化缓存量。通常根节点只有一个单页面,而其它节点使用 256KB 的 Multi-Page Block。
在一个两组件 LSM-Tree 中,只要 C0 组件足够大,那么就会有一个批量处理效果。例如,如果一条数据记录的大小是 16Bytes,在一个 4KB 的节点中将会有 250 条记录;如果 C0 组件的大小是 C1 的 1/25,那么在每个合并操作新产生的具有 250 条记录的 C1 节点中,将会有 10 条是从 C0 合并而来的新记录。也就是说用户新写入的数据暂时存储到内存的 C0 中,然后再批量延迟写入磁盘,相当于将用户之前的 10 次写入合并为一次写入。显然地,由于只需要一次随机写就可以写入多条数据,LSM-Tree 的写效率比 B-Tree 等数据结构更高,而 Rolling Merge 过程则是其中的关键。
Rolling Merge
我们可以把两组件 LSM-Tree 的 Rolling Merge 过程类比为一个具有一定步长的游标循环往复地穿越在 C0 和 C1 的键值对上,不断地从C0 中取出数据放入到磁盘上的 C1 中。
该游标在 C1树的叶子节点和索引节点上都有一个逻辑位置,在每个层级上,所有正在参与合并的 Multi-Page Blocks 将会被分成两种类型:Emptying Block的内部记录正在被移出,但是还有一些数据是游标所未到达的,Filling Block则存储着合并后的结果。类似地,该游标也会定义出Emptying Node和Filling Node,这两个节点都被缓存在内存中。为了可以进行并发访问,每个层级上的 Block 包含整数个节点,这样在对执行节点进行重组合并过程中,针对这些节点内部记录的访问将会被阻塞,但是同一 Block 中其它节点依然可以正常访问。
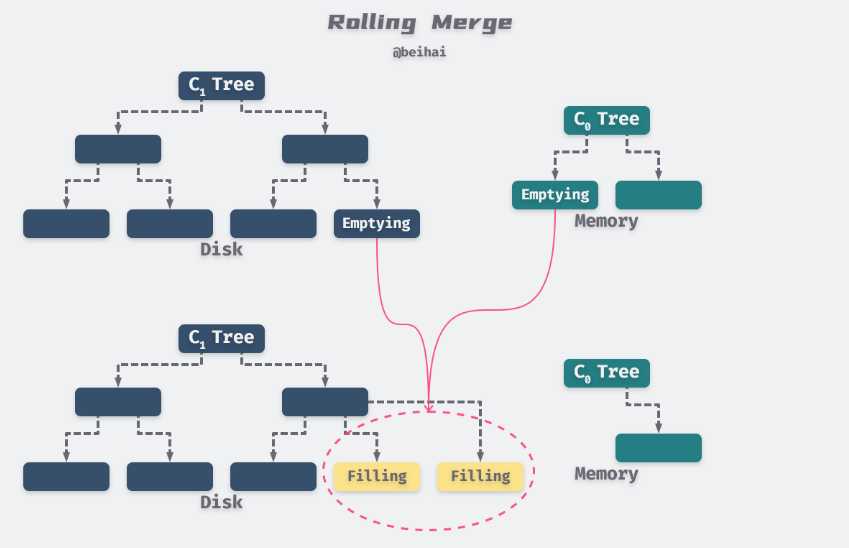
合并后的新 Blocks 会被写入到新的磁盘位置上,这样旧的 Blocks 就不会被覆盖,在发生 crash 后依然可以进行数据恢复。同时需要在索引节点中建立新的索引信息,为了进行恢复还需要产生一条日志记录。那些可能在恢复过程中需要的旧的 Block 暂时还不会被删除,只有当后续的写入提供了足够信息时它们才可以宣告失效。
C1中的父目录节点也会被缓存在内存中,实时更新以反映出叶子节点的变动,同时父节点还会在内存中停留一段时间以最小化 I/O。当合并步骤完成后,C1 中的旧叶子节点就会变为无效状态,随后会被从 C1 目录结构中删除。为了减少崩溃后的数据恢复时间,合并过程需要进行周期性的 checkpoint,强制将缓存信息写入磁盘。
为了让 LSM 读取速度相对较快,管理文件数量非常重要,因此我们要对文件进行合并压缩。在 LevelDB 中,合并后的大文件会进入下一个 Level 中。
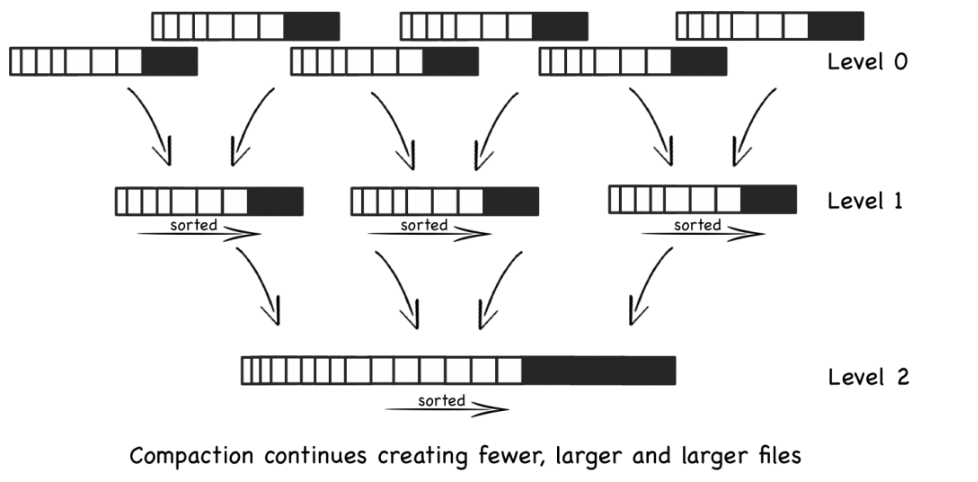
例如我们的 Level-0 中每个文件有 10 条数据,每 5 个 Level-0 文件合并到 1 个 Level1 文件中,每单个 Level1 文件中有 50 条数据(可能会略少一些)。而每 5 个 Level1 文件合并到 1 个 Level2 文件中,该过程会持续创建越来越大的文件,越旧的数据 Level 级数也会越来越高。
由于文件已排序,因此合并文件的过程非常快速,但是在等级越高的数据查询速度也越慢。在最坏的情况下,我们需要单独搜索所有文件才能读取结果。
数据读取
当在 LSM-Tree 上执行一个精确匹配查询或者范围查询时,首先会到 C0 中查找所需的值,如果在 C0 中没有找到,再去 C1 中查找。这意味着与 B-Tree 相比,会有一些额外的 CPU 开销,因为现在需要去两个目录中搜索。虽然每个文件都保持排序,可以通过比较该文件的最大/最小键值对来判断是否需要进行搜索。但是,随着文件数量的增加,每个文件都需要检查,读取还是会变得越来越慢。
因此,LSM-Tree 的读取速度比其它数据结构更慢。但是我们可以使用一些索引技巧进行优化。LevelDB 会在每个文件末尾保留块索引来加快查询速度,这比直接二进制搜索更好,因为它允许使用变长字段,并且更适合压缩数据。详细的内容会在 SSTable 小节中介绍。
我们还可以针对删除操作进行一些优化,高效地更新索引。例如通过断言式删除(Predicate Deletion)过程,只要简单地声明一个断言,就可以执行批量删除的操作方式。例如删除那些时间戳在 20 天前的所有的索引值,当位于 C1 组件的记录通过正常过的数据合并过程被加载到内存中时,就可以它们直接丢弃来实现删除。
除此之外,考虑到各种因素,针对 LSM-Tree 的并发访问方法必须解决如下三种类型的物理冲突:
- 查询操作不能同时去访问另一个进程的 Rolling Merge 正在修改的磁盘组件的节点内容;
- 针对 C0 组件的查询和插入操作也不能与正在进行的 Rolling Merge 的同时对树的相同部分进行访问;
- 在多组件 LSM-Tree 中,从 Ci-1 到 Ci 的 Rolling Merge 游标有时需要越过从 Ci 到 Ci+1 的 Rolling Merge 游标,因为数据从 Ci-1 移出速率 >= 从 Ci 移出的速率,这意味着 Ci-1 所关联的游标的循环周期要更快。因此无论如何,所采用的并发访问机制必须允许这种交错发生,而不能强制要求在交会点,移入数据到 Ci 的线程必须阻塞在从 Ci 移出数据的线程之后。
Multi-Component LSM-Tree
为了保证 C0 的大小维持在在阈值范围内,这要求 Rolling Merge 将数据合并到 C1 的速度必须不低于用户的写入速度,此时 C0 的不同大小会对整体性能造成不同的结果:
- C0 非常小:此时一条数据的插入都会使 C0 变满,从而触发 Rolling Merge,最坏的情况下,C0 的每一次插入都会导致 C1 的全部叶子节点被读进内存又写回磁盘,I/O 开销非常高;
- C0 非常大:此时基本没有 I/O 开销,但需要很大的内存空间,也不易进行数据恢复。
为了进一步缩小两组件 LSM-Tree 的开销平衡点,多组件 LSM-Tree 在 C0 和 C1 之间引入一组新的 Component,大小介于两者之间,逐级增长,这样 C0 就不用每次和 C1 进行 Rolling Merge,而是先和中间的组件进行合并,当中间的组件到达其大小限制后再和 C1 做 Rolling Merge,这样就可以在减少 C0 内存开销的同时减少磁盘 I/O 开销。有些类似于我们的多级缓存结构。
小节
LSM-Tree 的实现思路与常规存储系统采取的措施不太相同,其将随机写转化为顺序写,尽量保持日志型数据库的写性能优势,并提供相对较好的读性能。在大量写入场景下 LSM-Tree 之所以比 B-Tree、Hash 要好,得益于以下两个原因:
- Batch Write:由于采用延迟写,LSM-Tree 可以在 Rolling Merge 过程中,通过一次 I/O 批量向 C1 写入多条数据,那么这多条数据就均摊了这一次 I/O,减少磁盘的 I/O 开销;
- Multi-Page Block:LSM-Tree 的批量写可以有效地利用 Multi-Page Block,在 Rolling Merge 的过程中,一次从 C1 中读出多个连续的数据页与 C0 合并,然后一次向 C1 写回这些连续页面,这样只需要单次 I/O 就可以完成多个 Pages 的读写。
LSM Tree 组件介绍
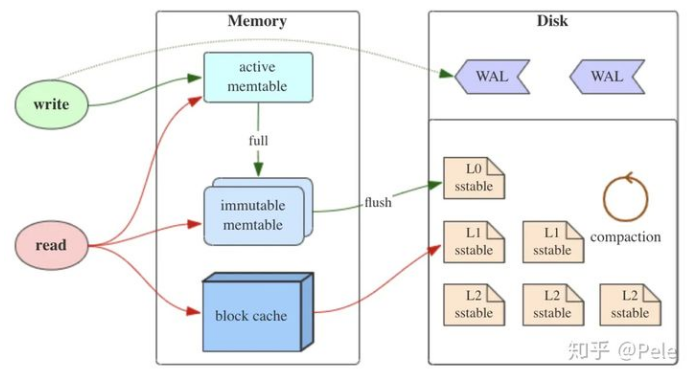
如上图所示,LSM树有以下三个重要组成部分:
MemTable
MemTable是在内存中的数据结构,用于保存最近更新的数据,会按照Key有序地组织这些数据,LSM树对于具体如何组织有序地组织数据并没有明确的数据结构定义,例如Hbase使跳跃表来保证内存中key的有序。因为数据暂时保存在内存中,内存并不是可靠存储,如果断电会丢失数据,因此通常会通过WAL(Write-ahead logging,预写式日志)的方式来保证数据的可靠性。
Immutable MemTable
当 MemTable达到一定大小后,会转化成Immutable MemTable。Immutable MemTable是将转MemTable变为SSTable的一种中间状态。写操作由新的MemTable处理,在转存过程中不阻塞数据更新操作。
SSTable(Sorted String Table)
有序键值对集合,是LSM树组在磁盘中的数据结构。为了加快SSTable的读取,可以通过建立key的索引以及布隆过滤器来加快key的查找。

这里需要关注一个重点,LSM树(Log-Structured-Merge-Tree)正如它的名字一样,LSM树会将所有的数据插入、修改、删除等操作记录(注意是操作记录)保存在内存之中,当此类操作达到一定的数据量后,再批量地顺序写入到磁盘当中。这与B+树不同,B+树数据的更新会直接在原数据所在处修改对应的值,但是LSM数的数据更新是日志式的,当一条数据更新是直接append一条更新记录完成的。这样设计的目的就是为了顺序写,不断地将Immutable MemTable flush到持久化存储即可,而不用去修改之前的SSTable中的key,保证了顺序写。
因此当MemTable达到一定大小flush到持久化存储变成SSTable后,在不同的SSTable中,可能存在相同Key的记录,当然最新的那条记录才是准确的。这样设计的虽然大大提高了写性能,但同时也会带来一些问题:
1 冗余存储,对于某个key,实际上除了最新的那条记录外,其他的记录都是冗余无用的,但是仍然占用了存储空间。因此需要进行Compact操作(合并多个SSTable)来清除冗余的记录。 2 读取时需要从最新的倒着查询,直到找到某个key的记录。最坏情况需要查询完所有的SSTable,这里可以通过前面提到的索引/布隆过滤器来优化查找速度。
LSM树的Compact策略
从上面可以看出,Compact操作是十分关键的操作,否则SSTable数量会不断膨胀。在Compact策略上,主要介绍两种基本策略:size-tiered和leveled。 不过在介绍这两种策略之前,先介绍三个比较重要的概念,事实上不同的策略就是围绕这三个概念之间做出权衡和取舍。
读放大:读取数据时实际读取的数据量大于真正的数据量。例如在LSM树中需要先在MemTable查看当前key是否存在,不存在继续从SSTable中寻找。 写放大:写入数据时实际写入的数据量大于真正的数据量。例如在LSM树中写入时可能触发Compact操作,导致实际写入的数据量远大于该key的数据量。 空间放大:数据实际占用的磁盘空间比数据的真正大小更多。上面提到的冗余存储,对于一个key来说,只有最新的那条记录是有效的,而之前的记录都是可以被清理回收的。
1) size-tiered 策略
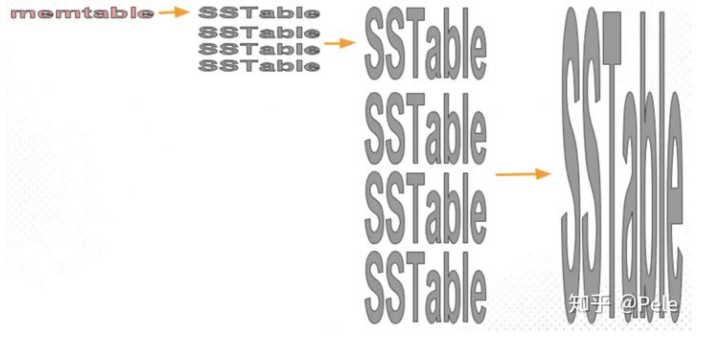
size-tiered策略保证每层SSTable的大小相近,同时限制每一层SSTable的数量。如上图,每层限制SSTable为N,当每层SSTable达到N后,则触发Compact操作合并这些SSTable,并将合并后的结果写入到下一层成为一个更大的sstable。 由此可以看出,当层数达到一定数量时,最底层的单个SSTable的大小会变得非常大。并且size-tiered策略会导致空间放大比较严重。即使对于同一层的SSTable,每个key的记录是可能存在多份的,只有当该层的SSTable执行compact操作才会消除这些key的冗余记录。
2) leveled策略
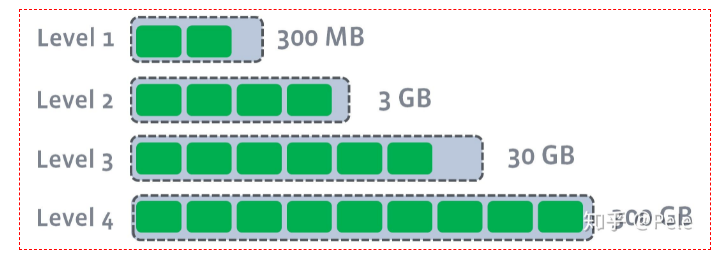 leveled策略也是采用分层的思想,每一层限制总文件的大小。
但是跟size-tiered策略不同的是,leveled会将每一层切分成多个大小相近的SSTable。这些SSTable是这一层是全局有序的,意味着一个key在每一层至多只有1条记录,不存在冗余记录。之所以可以保证全局有序,是因为合并策略和size-tiered不同,接下来会详细提到。
leveled策略也是采用分层的思想,每一层限制总文件的大小。
但是跟size-tiered策略不同的是,leveled会将每一层切分成多个大小相近的SSTable。这些SSTable是这一层是全局有序的,意味着一个key在每一层至多只有1条记录,不存在冗余记录。之所以可以保证全局有序,是因为合并策略和size-tiered不同,接下来会详细提到。
假设存在以下这样的场景:
L1的总大小超过L1本身大小限制:
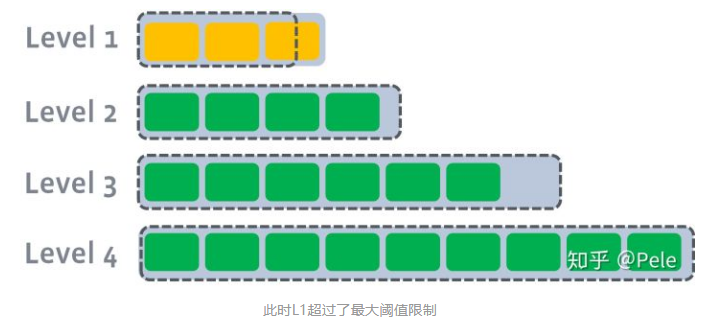
此时会从L1中选择至少一个文件,然后把它跟L2有交集的部分(非常关键)进行合并。生成的文件会放在L2:
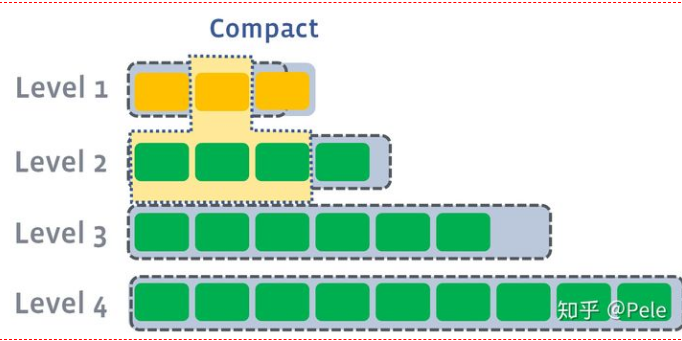 如上图所示,此时L1第二SSTable的key的范围覆盖了L2中前三个SSTable,那么就需要将L1中第二个SSTable与L2中前三个SSTable执行Compact操作。
如上图所示,此时L1第二SSTable的key的范围覆盖了L2中前三个SSTable,那么就需要将L1中第二个SSTable与L2中前三个SSTable执行Compact操作。如果L2合并后的结果仍旧超出L2的阈值大小,需要重复之前的操作 —— 选至少一个文件然后把它合并到下一层:
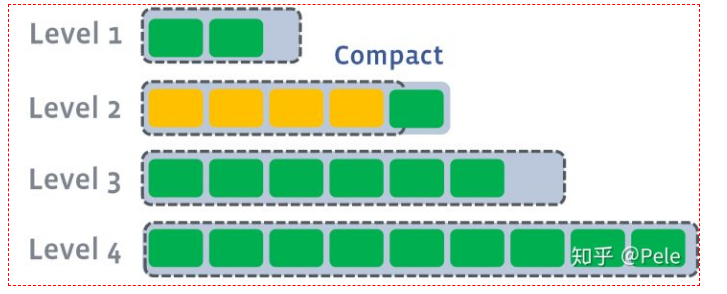 需要注意的是,多个不相干的合并是可以并发进行的:
需要注意的是,多个不相干的合并是可以并发进行的:
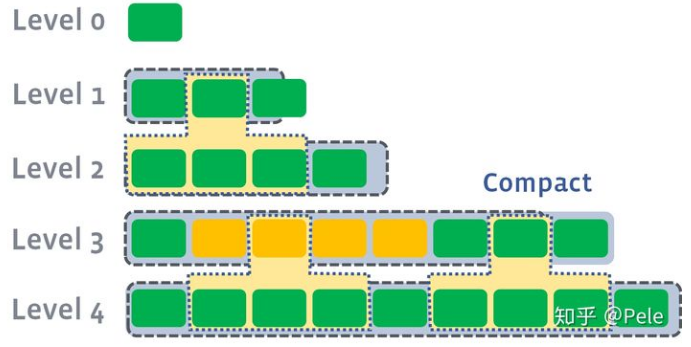
leveled策略相较于size-tiered策略来说,每层内key是不会重复的,即使是最坏的情况,除开最底层外,其余层都是重复key,按照相邻层大小比例为10来算,冗余占比也很小。因此空间放大问题得到缓解。但是写放大问题会更加突出。举一个最坏场景,如果LevelN层某个SSTable的key的范围跨度非常大,覆盖了LevelN+1层所有key的范围,那么进行Compact时将涉及LevelN+1层的全部数据。