一,SQL语句性能优化
对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
应尽量避免在 where 子句中对字段进行 null 值判断,创建表时NULL是默认值,但大多数时候应该使用NOT NULL,或者使用一个特殊的值,如0,-1作为默 认值。
应尽量避免在 where 子句中使用!=或<>操作符, MySQL只有对以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE
应尽量避免在 where 子句中使用 or 来连接条件, 否则将导致引擎放弃使用索引而进行全表扫描, 可以 使用UNION合并查询: select id from t where num=10 union all select id from t where num=20
in 和 not in 也要慎用,否则会导致全表扫描,对于连续的数值,能用 between 就不要用 in 了:Select id from t where num between 1 and 3
下面的查询也将导致全表扫描:select id from t where name like ‘%abc%’ 或者select id from t where name like ‘%abc’若要提高效率,可以考虑全文检索。而select id from t where name like ‘abc%’ 才用到索引
如果在 where 子句中使用参数,也会导致全表扫描。
应尽量避免在 where 子句中对字段进行表达式操作,应尽量避免在where子句中对字段进行函数操作
很多时候用 exists 代替 in 是一个好的选择: select num from a where num in(select num from b).用下面的语句替换: select num from a where exists(select 1 from b where num=a.num)
索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要
应尽可能的避免更新 clustered 索引数据列, 因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
尽可能的使用 varchar/nvarchar 代替 char/nchar , 因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
最好不要使用”“返回所有: select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
使用表的别名(Alias):当在SQL语句中连接多个表时,请使用表的别名并把别名前缀于每个Column上.这样一来,就可以减少解析的时间并减少那些由Column歧义引起的语法错误。
使用“临时表”暂存中间结果 简化SQL语句的重要方法就是采用临时表暂存中间结果,但是,临时表的好处远远不止这些,将临时结果暂存在临时表,后面的查询就在tempdb中了,这可以避免程序中多次扫描主表,也大大减少了程序执行中“共享锁”阻塞“更新锁”,减少了阻塞,提高了并发性能。
一些SQL查询语句应加上nolock,读、写是会相互阻塞的,为了提高并发性能,对于一些查询,可以加上nolock,这样读的时候可以允许写,但缺点是可能读到未提交的脏数据。使用 nolock有3条原则。查询的结果用于“插、删、改”的不能加nolock !查询的表属于频繁发生页分裂的,慎用nolock !使用临时表一样可以保存“数据前影”,起到类似Oracle的undo表空间的功能,能采用临时表提高并发性能的,不要用nolock 。
常见的简化规则如下:不要有超过5个以上的表连接(JOIN),考虑使用临时表或表变量存放中间结果。少用子查询,视图嵌套不要过深,一般视图嵌套不要超过2个为宜。
将需要查询的结果预先计算好放在表中,查询的时候再Select。这在SQL7.0以前是最重要的手段。例如医院的住院费计算。
尽量使用exists代替select count(1)来判断是否存在记录,count函数只有在统计表中所有行数时使用,而且count(1)比count(*)更有效率。
尽量使用“>=”,不要使用“>”
索引的使用规范:索引的创建要与应用结合考虑,建议大的OLTP表不要超过6个索引;尽可能的使用索引字段作为查询条件,尤其是聚簇索引,必要时可以通过index index_name来强制指定索引;避免对大表查询时进行table scan,必要时考虑新建索引;在使用索引字段作为条件时,如果该索引是联合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用;要注意索引的维护,周期性重建索引,重新编译存储过程。
二、索引问题
法则:不要在建立的索引的数据列上进行下列操作:
◆避免对索引字段进行计算操作
◆避免在索引字段上使用not,<>,!=
◆避免在索引列上使用IS NULL和IS NOT NULL
◆避免在索引列上出现数据类型转换
◆避免在索引字段上使用函数
◆避免建立索引的列中使用空值。
1. 什么是最左前缀原则?
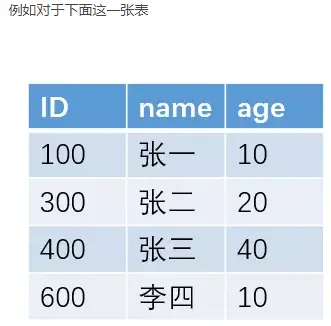
如果我们按照 name 字段来建立索引的话,采用B+树的结构,大概的索引结构如下:
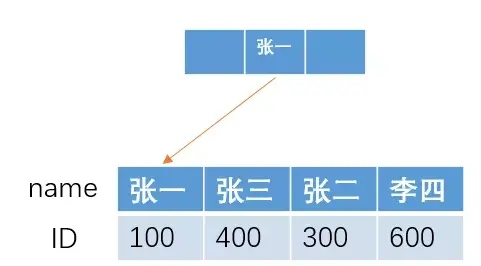
如果我们要进行模糊查找,查找name 以“张"开头的所有人的ID,即 sql 语句为
1select ID from table where name like '张%'
由于在B+树结构的索引中,索引项是按照索引定义里面出现的字段顺序排序的,索引在查找的时候,可以快速定位到 ID 为 100的张一,然后直接向右遍历所有张开头的人,直到条件不满足为止。
也就是说,我们找到第一个满足条件的人之后,直接向右遍历就可以了,由于索引是有序的,所有满足条件的人都会聚集在一起。
而这种定位到最左边,然后向右遍历寻找,就是我们所说的最左前缀原则。
2. 为什么用 B+ 树做索引而不用哈希表做索引?
1、哈希表是把索引字段映射成对应的哈希码然后再存放在对应的位置,这样的话,如果我们要进行模糊查找的话,显然哈希表这种结构是不支持的,只能遍历这个表。而B+树则可以通过最左前缀原则快速找到对应的数据
2、如果我们要进行范围查找,例如查找ID为100 ~ 400的人,哈希表同样不支持,只能遍历全表。
3、索引字段通过哈希映射成哈希码,如果很多字段都刚好映射到相同值的哈希码的话,那么形成的索引结构将会是一条很长的链表,这样的话,查找的时间就会大大增加。
3. 主键索引和非主键索引有什么区别?
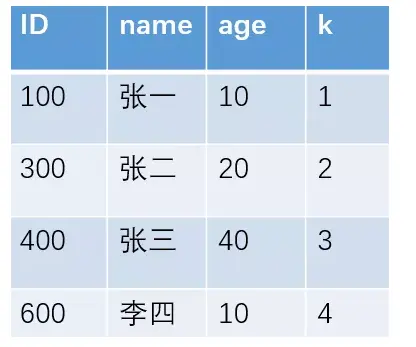
例如对于下面这个表(其实就是上面的表中增加了一个k字段),且ID是主键。
主键索引和非主键索引的示意图如下:
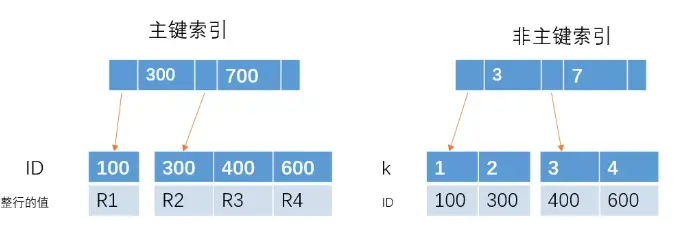
从图中不难看出,主键索引和非主键索引的区别是:非主键索引的叶子节点存放的是主键的值,而主键索引的叶子节点存放的是整行数据,其中非主键索引也被称为二级索引,而主键索引也被称为聚簇索引。
图中左边表示主键索引,右边表示非主键索引,图中的R1,R2等都表示整行的数据内容。从图中可以看出,主键索引保存的都是整行的数据内容,而非主键索引则保存的都是所在行的行id。 这也就是说,当查询时,以主键索引查询,会直接返回主键索引对应的整行数据;而以非主键索引查询时,会先返回当前索引对应的行id,然后根据行id去查询对应的整行数据。 所以以主键索引当查询条件会比比非主键索引当查询条件快。最后无论是主键索引还是非主键索引,查询速度都会比用普通字段快。
根据这两种结构我们来进行下查询,看看他们在查询上有什么区别。
1、如果查询语句是 select * from table where ID = 100,即主键查询的方式,则只需要搜索 ID 这棵 B+树。
2、如果查询语句是 select * from table where k = 1,即非主键的查询方式,则先搜索k索引树,得到ID=100,再到ID索引树搜索一次,这个过程也被称为回表。
4. 为什么建议使用主键自增的索引?
对于这颗主键索引的树
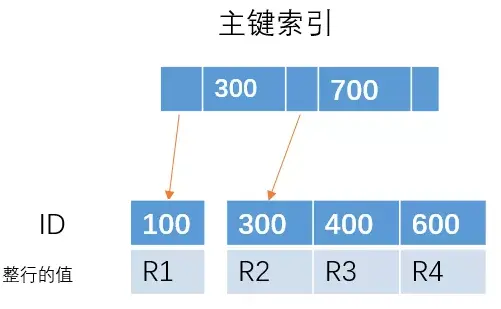
如果我们插入 ID = 650 的一行数据,那么直接在最右边插入就可以了
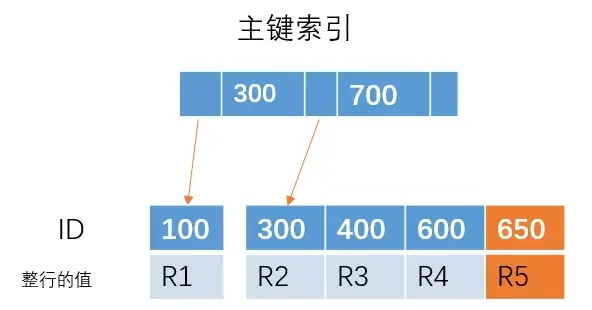
但是如果插入的是 ID = 350 的一行数据,由于 B+ 树是有序的,那么需要将下面的叶子节点进行移动,腾出位置来插入 ID = 350 的数据,这样就会比较消耗时间,如果刚好 R4 所在的数据页已经满了,需要进行页分裂操作,这样会更加糟糕。
但是,如果我们的主键是自增的,每次插入的 ID 都会比前面的大,那么我们每次只需要在后面插入就行, 不需要移动位置、分裂等操作,这样可以提高性能。也就是为什么建议使用主键自增的索引。
三、表的设计
0、必须使用默认的InnoDB存储引擎–支持事务、行级锁、并发性能好、CPU及内存缓存页优化使得资源利用率高 1、表和字段使用中文注释–便于后人理解 2、使用默认utf8mb4字符集–标准、万国码、无乱码风险、无需转码 3、禁止使用触发器、视图、存储过程和event 4、禁止使用外键–外键导致表之间的耦合,update和delete操作都会涉及相关表,影响性能 –架构方向:对数据库性能影响较大的特性少用;应将计算集中在服务层,解放数据库CPU;数据库擅长索引和存储,勿让数据库背负重负 5、禁止存大文件或者照片–在数据库里存储URI 字段: 6、必须把字段定义为NOT NULL并设置默认值–null值需要更多的存储空间; 字段中有null值的话,name != ‘san’ 查询结果中不包含name is null的记录 7、禁止使用TEXT/BOLB字段类型–浪费磁盘和内存空间,非必要的大量的大字段查询导致内存命中率降低,影响数据库性能 索引: 8、单表索引控制在5个以内 9、单索引不超过5个字段–超过5个以及起不到有效过滤数据的效果 10、建立组合索引,必须把区分度高的字段放在前边–更加有效的过滤数据 11、数据区分度不大的字段不易使用索引–例如:性别只有男,女,订单状态,每次过滤数据很少
四、SQL查询规范:
1、禁止使用select *,只获取需要的字段–查询很多无用字段,增加CPU/IO/NET消耗;不能有效的利用覆盖索引;增删字段易出bug 2、禁止使用属性的隐式转换select * from customer where phone=123123–会导致全表扫描,不能命中索引 3、禁止在where条件上使用函数和计算 4、禁止负向查询(NOT != <> !< !> MOT IN NOT LIKE)和%开头的like(前导模糊查询)–会导致全表扫描 5、禁止大表使用JOIN查询和子查询–会产生临时表,消耗较多CPU和内存,影响数据库性能 6、在属性上进行计算不能命中索引–如 select * from order where YEAR(date) <= ‘2017’不能命中索引导致全表扫描 7、复合索引最左前缀–例如user 表建立了(userid,phone)的联合索引 有如下几种写法: (1)select * from user where userid = ? and phone = ? (2)select * from user where phone=? and userid= ? (3)select * from user where phone = ? (4)select * from user where userid = ? 其中(1)(2)(4)可以命中索引,(3)会导致全表扫描