简介
RocksDB 是由 Facebook 基于 LevelDB 开发的一款提供键值存储与读写功能的 LSM-tree 架构引擎。用户写入的键值对会先写入磁盘上的 WAL (Write Ahead Log),然后再写入内存中的跳表(SkipList,这部分结构又被称作 MemTable)。LSM-tree 引擎由于将用户的随机修改(插入)转化为了对 WAL 文件的顺序写,因此具有比 B 树类存储引擎更高的写吞吐。
内存中的数据达到一定阈值后,会刷到磁盘上生成 SST 文件 (Sorted String Table),SST 又分为多层(默认至多 6 层),每一层的数据达到一定阈值后会挑选一部分 SST 合并到下一层,每一层的数据是上一层的 10 倍(因此 90% 的数据存储在最后一层)。
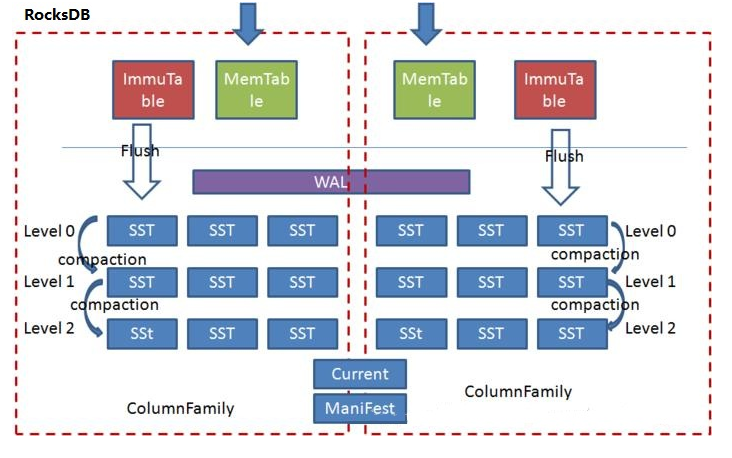
RocksDB 允许用户创建多个 ColumnFamily ,这些 ColumnFamily 各自拥有独立的内存跳表以及 SST 文件,但是共享同一个 WAL 文件,这样的好处是可以根据应用特点为不同的 ColumnFamily 选择不同的配置,但是又没有增加对 WAL 的写次数。
rocksdb 和 leveldb对比优势
- Leveldb是单线程合并文件,Rocksdb可以支持多线程合并文件,充分利用多核的特性,加快文件合并的速度,避免文件合并期间引起系统停顿
- Leveldb只有一个Memtable,若Memtable满了还没有来得及持久化,则会引起系统停顿,Rocksdb可以根据需要开辟多个Memtable;
- Leveldb只能获取单个K-V,Rocksdb支持一次获取多个K-V。
- Levledb不支持备份,Rocksdb支持全量和备份。
架构
RocksDB 是基于 LSM-Tree 的。Rocksdb结构图如下:
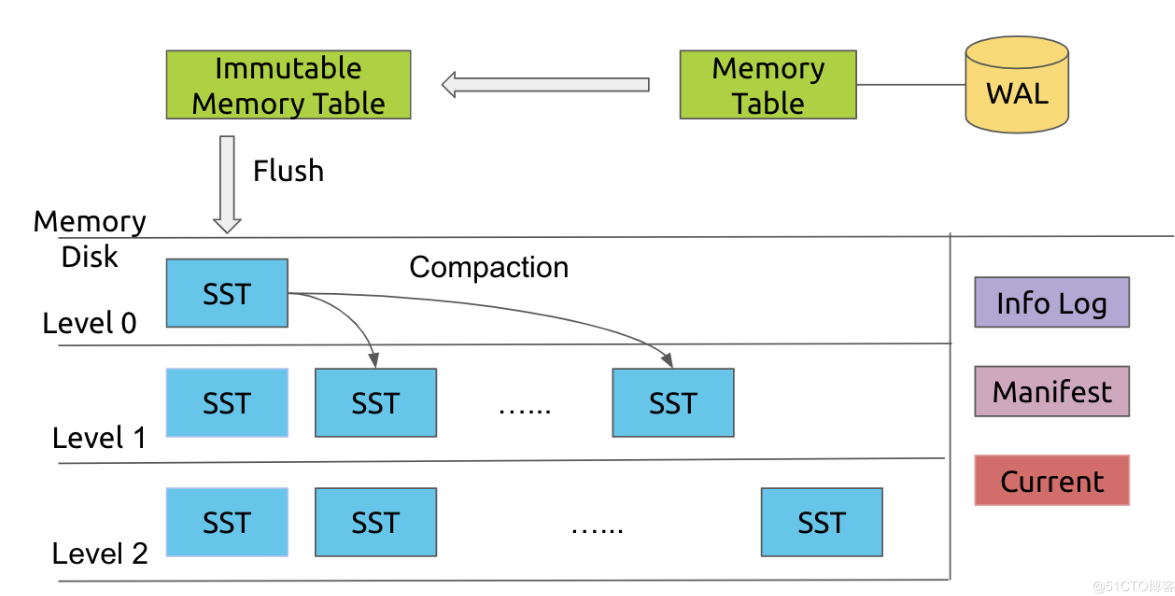
- LSM-Tree 能将离散的随机写请求都转换成批量的顺序写请求(WAL + Compaction),以此提高写性能。
- sst文件是在硬盘上的。SST files按照key 排序,且每个文件的key range互相不重叠。为了check一个key可能存在于哪一个一个SST file中,RocksDB并没有依次遍历每一个SST file,然后去检查key是否在这个file的key range 内,而是执行二分搜索算法(FileMetaData.largest )去定位这个SST file。
- 任何的写入都会先写到 WAL,然后在写入 Memory Table(Memtable)。当然为了性能,也可以不写入 WAL,但这样就可能面临崩溃丢失数据的风险。
- 当一个 Memtable 写满了之后,就会变成 immutable 的 Memtable,RocksDB 在后台会通过一个 flush 线程将这个 Memtable flush 到磁盘,生成一个 Sorted String Table(SST) 文件,放在 Level 0 层。当 Level 0 层的 SST 文件个数超过阈值之后,就会通过 Compaction 策略将其放到 Level 1 层,以此类推。
- 这里关键就是 Compaction,如果没有 Compaction,那么写入是非常快的,但会造成读性能降低,同样也会造成很严重的空间放大问题。对于 RocksDB 来说,他有三种 Compaction 策略,一种就是默认的 Leveled Compaction,另一种就是 Universal Compaction,也就是常说的 Size-Tired Compaction,还有一种就是 FIFO Compaction。对于 FIFO 来说,它的策略非常的简单,所有的 SST 都在 Level 0,如果超过了阈值,就从最老的 SST 开始删除,其实可以看到,这套机制非常适合于存储时序数据。
- 实际对于 RocksDB 来说,它其实用的是一种 Hybrid 的策略,在 Level 0 层,它其实是一个 Size-Tired 的,而在其他层就是 Leveled 的。
- RocksDB收到写入请求时,会直接将数据写入内存即RocksDB定义的区域Memtable,以及WAL(Write Ahead Logging,防止服务重置导致的数据丢失)中,当写入Memtable的数据达到阈值,则转为不可写入状态Immutable,同时申请新的Memtable供上层应用继续写入。RocksDB会通过异步的方式将数据Flush到SST数据文件中,RocksDB对SST文件的编排就采用了LSM树的管理方式,每层SST到达阈值,RocksDB会启动异步线程进行Compaction操作,将文件内的末端节点数据进行合并到下一层SST的文件中。
写入流程
- 首先当一条数据写入rocksdb时, 会将这条记录封装成一个batch, 也可以是多条记录一个batch,由batch来保证原子操作。就是一个batch里的数据要么全部成功要么全部失败。
- 第一步先以日志的形式落地磁盘,记write ahead log -> .wal 文件。
- 落地成功后再写入memtable。
1.这里记录wal的原因就是防止重启时内存中的数据丢失。所以在db重新打开时会先从wal恢复内存中的memtable. 可配置WAL保存在可靠的存储里。 2.这里的memtable是在内存中的一个跳表结构(skiplist)。每一个节点都是存储着一个key, value. 跳表可使查找的复杂度为logn, 同时插入数据非常简单。每个batch独占memtable的写锁。这个是为了避免多线程写造成的数据错乱。
- 当memtable的数据大小超过阈值(write_buffer_size)后,会新生成一个memtable继续写,将前一个memtable保存为只读memtable -> immutabel.
- 当只读memtable的数量超过阈值后,会将所有的只读memtable合并并flush到磁盘生成一个SST文件。这里的SST属于level0, level0中的每个SST有序,整个level0不一定有序。
- 当level0的sst文件数超过阈值或者总大小超过阈值,会触发compaction操作,将level0中的数据合并到level1中。同样level1的文件数超过阈值或者总大小超过阈值,也会触发compaction操作, 这时候随机选择一个sst合并到更高层的level中。
1:level1 及其以上的level都整体有序。每个sst存储一个范围的数据互不交叉互不重合; 2: level1 以上的 compaction操作可以多线程执行,前提是每个线程所操作的数据互不交叉。
读取流程
RocksDB中的每一条记录(KeyValue)都有一个lsn(LogSequenceNumber),从最初的0开始,每次写入加1。lsn在memtable中单调递增。
- 首先读操作先访问memtable。跳表的时间复杂度可达到logn。
- 如果不存在会访问level0, 而level0整体不是有序的, 所以会按创建时间由新到老依次访问每一个sst文件。所以时间复杂度为m*logn。
- 如果仍不存在,则继续访问level1,由于level1及其以上的level都整体有序,所以只需要访问一个sst文件即可。 直到查找到最高层或者找到这个key。所以读操作可能会被放大好多倍。
总结: 读取的顺序为memtable->immutable memtable->level 0 SST->…->level n SST。其中,memtable和immutable memtable采用了跳表特性进行查询,SST文件中有过滤器(布隆过滤器)决定是否包含某个key再加载至内存,基于有序KV进行二分查找。同时,在memtable和SST之上还设置了Block Cache,提高查询性能。
rocksdb的compaction
- 读放大(Read Amplification)。读取数据时实际读取的数据量大于真正的数据量。LSM-Tree 的读操作需要从新到旧(从上到下)一层一层查找,直到找到想要的数据。这个过程可能需要不止一次 I/O。特别是 range query 的情况,影响很明显。
- 空间放大(Space Amplification)。数据实际占用的磁盘空间比数据的真正大小更多。因为所有的写入都是顺序写(append-only)的,不是 in-place update ,所以过期数据不会马上被清理掉。
- 写放大。写入数据时实际写入的数据量大于真正的数据量。实际写入 HDD/SSD 的数据大小和程序要求写入数据大小之比。正常情况下,HDD/SSD 观察到的写入数据多于上层程序写入的数据。
compaction特性:
RocksDB 和 LevelDB 通过后台的 compaction 来减少读放大(减少 SST 文件数量)和空间放大(清理过期数据)。 写放大(Write Amplification) 的问题。compaction其实就是以写放大作为代价,换取更好的读取性能。
在 HDD 作为主流存储的时代,RocksDB 的 compaction 带来的写放大问题并没有非常明显。这是因为:
HDD 顺序读写性能远远优于随机读写性能,足以抵消写放大带来的开销。 HDD 的写入量基本不影响其使用寿命。 现在 SSD 逐渐成为主流存储,compaction 带来的写放大问题显得越来越严重:
SSD 顺序读写性能比随机读写性能好一些,但是差距并没有 HDD 那么大。所以,顺序写相比随机写带来的好处,能不能抵消写放大带来的开销,这是个问题。 SSD 的使用寿命和其写入量有关,写放大太严重会大大缩短 SSD 的使用寿命。因为 SSD 不支持覆盖写,必须先擦除(erase)再写入。而每个 SSD block(block 是 SSD 擦除操作的基本单位) 的平均擦除次数是有限的。
rocksdb做了几点优化:
- 一点是为每个SST提供一个可配置的bloomfilter. 每个level的配置不一样。这样可以快速的确认一个key在不在某个SST中,这点以牺牲磁盘空间来换取时间。
- 另一点是提供可配置的cache, 用于保存访问过的key在内存中, 它缓存的是某个key在SST文件中的整个block里的记录。